Java 响应式编程-WebFlux并发模型
概述
Spring WebFlux 是 Spring Framework 5.0 引入的响应式 Web 框架,其核心优势在于能够以极少的硬件资源处理极高的并发量。要真正理解 WebFlux,必须彻底摒弃传统的 Spring MVC(Servlet)思维模式,深入理解其底层的异步非阻塞IO(NIO)和事件循环(Event Loop)机制。
SpringMVC线程模型
Spring MVC 使用同步编程模型,其中每个请求都被映射到一个线程,该线程负责将响应返回给请求套接字。当应用程序进行一些网络调用时,例如从数据库获取数据、从其他应用程序获取响应、文件读写等,请求线程必须等待才能获得所需的响应。此时,请求线程会被阻塞,CPU 利用率为零。这就是为什么该模型使用大型线程池来处理请求的原因。对于请求频率较低的应用程序来说,这可能没什么问题,但对于请求频率较高的应用程序来说,最终会导致应用程序运行缓慢甚至无响应,这无疑会对当今市场上的业务造成影响。
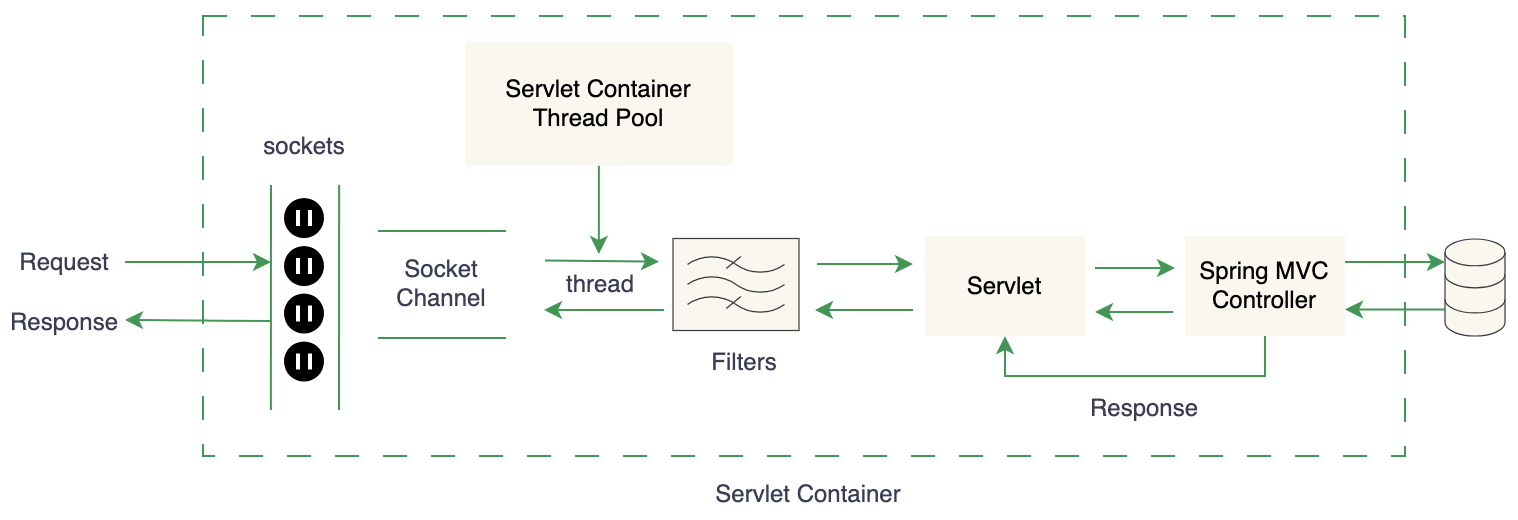
在SpringMVC中,多个用户请求可以被多个线程同时处理,在如今的多核处理器上有着明显的优势,这种并发模型也被称为 thread-per-request model (一个请求对应一个线程),基于线程的并发模型为我们解决了部分问题,但它并不能解决我们在单个线程内进行的大多数交互仍在阻塞的事实。此外,就上下文切换而言,线程过多导致在Java中实现并发的本机线程的成本很高。随着Web应用程序面临越来越多的请求,thread-per-request model 模型并不能满足这种并发量。
SpringWebFlux线程模型概述
Spring Webflux 默认使用 Netty 作为嵌入式服务器。除此之外,它还支持 Tomcat、Jetty、Undertow 和其他 Servlet 3.1+(Servlet 3 引入了异步编程功能,Servlet 3.1 还引入了异步 I/O) 容器,其中Netty 和 Undertow 并非 Servlet 运行时环境,而 Tomcat 和 Jetty 则是知名的 Servlet 容器。Spring Webflux使用响应式编程,调用数据库操作不会阻塞调用方线程,而是返回一个可以被其他线程订阅的Publisher对象,Subscriber可以在数据操作完成后得到通知。Spring Webflux其底层模型核心就是:异步非阻塞IO(NIO)和事件循环(Event Loop)机制。
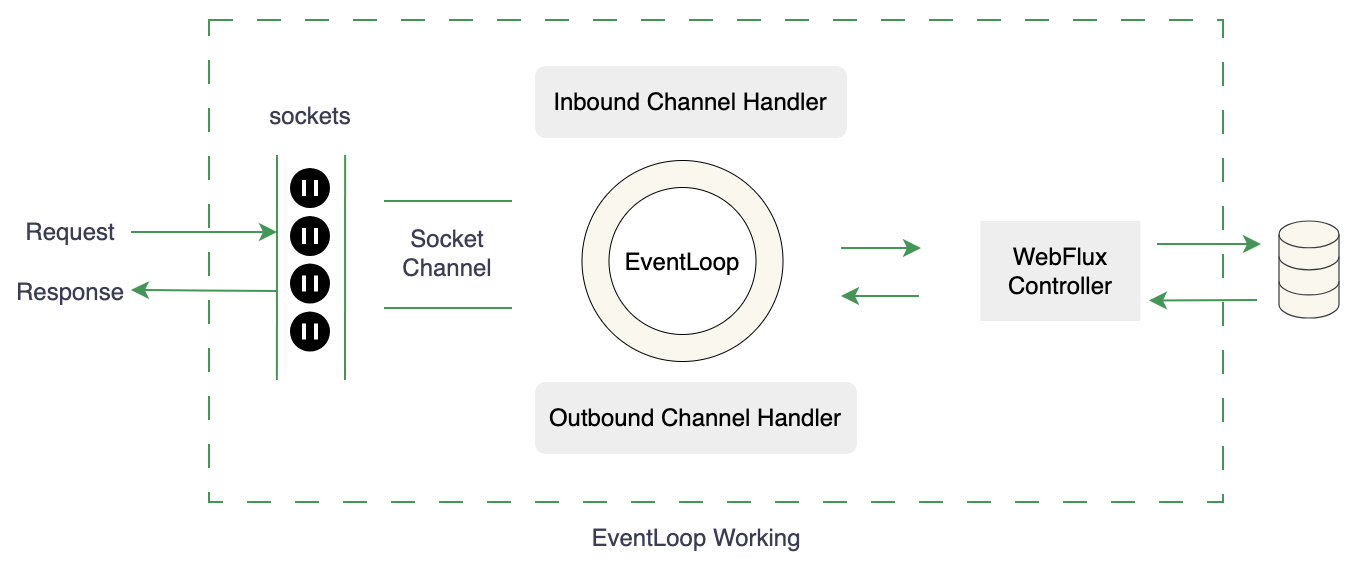
- 事件循环 (Event Loop):这是WebFlux的核心机制。少数专用的事件循环线程(在默认的Netty服务器中通常为 reactor-http-nio-* 线程)负责处理传入的请求、执行非阻塞业务逻辑,并将结果写回响应。
- 非阻塞 I/O:当一个请求需要等待I/O操作(例如数据库查询或外部服务调用)时,事件循环线程不会阻塞等待,而是去处理其他请求。一旦I/O操作完成,结果会作为一个事件返回给事件循环线程继续处理。
- Project Reactor:WebFlux使用Reactor库来管理异步数据流,提供了 Mono (0或1个元素) 和 Flux (0到N个元素) 类型。这些类型允许以响应式方式组合异步逻辑。
基于此,Spring WebFlux主要使用以下几种线程池:
- Event Loop Threads(事件循环线程):由底层服务器(如Netty,默认配置数量约为 可用处理器核心数 * 2)管理,处理所有传入的HTTP请求和出站响应,在事件循环线程中,这些线程绝不能被阻塞,任何阻塞操作都应当转移到单独的线程池中。
- Scheduler Threads(调度器线程):由Project Reactor提供,用于执行可能阻塞或CPU密集型任务。可以使用 subscribeOn() 或 publishOn() 操作符切换到不同的调度器。常用的调度器包括:
- Schedulers.parallel():用于CPU密集型任务,线程数通常等于CPU核心数。
- Schedulers.boundedElastic():用于I/O密集型或阻塞操作(如传统的JDBC调用、文件I/O),线程池大小会弹性伸缩以避免事件循环线程阻塞。
WebFlux处理流程(以netty为例):
- Request 到达: Netty 的 Selector 接收到 TCP 连接请求。
- 派发: 请求被交给 Event Loop 线程池中的某个线程。
- 处理链: 该线程执行一系列非阻塞的操作(Filter -> Controller -> Service)。
- I/O处理:发起数据库查询(使用 R2DBC 或 Reactive Redis 等响应式驱动)。当前线程不等待结果,而是注册一个“回调”(Callback/Subscription),然后立刻释放去处理其他请求。
- I/O 完成: 当数据库返回数据时,操作系统触发中断,Event Loop 收到通知。
- 恢复执行: 某个 Event Loop 线程(不一定是之前那个)捡起之前的上下文,执行剩下的逻辑,并将响应写回客户端。
事件循环 (Event Loop)
Java 中的以Netty的EventLoop为例,其核心原理是:使用一个专用的单线程结合 NIO Selector,以非阻塞的方式高效管理和处理多个网络连接的 I/O 事件和排队任务。它通过事件驱动和异步机制,实现了极高的可伸缩性和性能,特别适合构建高性能的网络服务器。
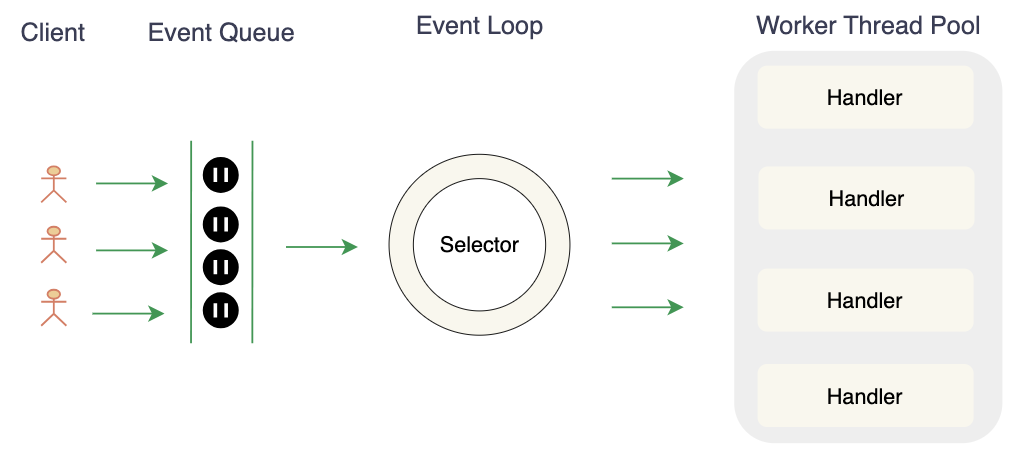
上图中Event Loop处理特点:
- 单线程执行:每个 EventLoop 实例都绑定到一个且仅一个 Java 线程(通常由 NioEventLoop 实现),并且在其整个生命周期内都不会改变。这种设计消除了大部分并发同步开销,因为所有与该 EventLoop 绑定的 Channel (连接) 的事件处理都在这个单线程内顺序执行。
- 多路复用:EventLoop 使用底层操作系统提供的 I/O 模型(例如 Java NIO Selector)实现多路复用。Selector 能够让一个线程同时监控大量的网络通道 (Channel),检查哪些通道已经准备好进行读、写、连接接受等操作,而无需阻塞等待。EventLoop 线程会周期性地调用 Selector.select() 方法来轮询事件。如果当前没有事件准备好,线程会进入休眠状态,直到操作系统通知有事件发生,从而避免了 CPU 空转。
- 事件驱动:EventLoop 通过监听与 Channel 相关的 I/O 事件,并将其转化为事件对象(例如 ChannelReadEvent、ChannelWriteEvent 等)进行处理。当 Selector 准备好事件(如数据可读)时,EventLoop 会将控制权交给相应的处理器 (Handler),执行读取数据和业务逻辑等操作。用户代码或业务逻辑可以向 EventLoop 提交 Runnable 或 Callable 任务(如定时任务或 CPU 密集型任务的委派)。这些任务会被放入任务队列中。
- 非阻塞操作:EventLoop 中所有的操作都是非阻塞的,包括 I/O 操作和异步任务的执行。这样可以确保整个系统始终处于高效运行状态,并提高了系统的可伸缩性。
EventLoop 的核心是一个无限循环的执行逻辑,通常遵循以下步骤:
- 轮询 I/O 事件: 检查是否有新的网络事件就绪(使用 Selector)。
- 处理 I/O 事件: 将就绪的 I/O 事件分派给绑定的 ChannelPipeline 中的 Handler 进行处理。
- 处理任务队列: I/O 事件处理完毕后,执行任务队列中的待处理任务,包括用户提交的任务和定时任务。
- 循环往复: 重复以上过程。
Scheduler Threads
WebFlux的Scheduler使用的是 Project Reactor 的 Scheduler。Scheduler 充当任务执行的“执行器”或“调度器”,允许开发者在响应式链中的特定点(通过 publishOn 或 subscribeOn 操作符)显式切换执行任务的线程上下文。WebFlux 旨在实现全程非阻塞,但在不得不执行阻塞 I/O 或 CPU 密集型任务时,应该使用特定的 Scheduler(如 Schedulers.boundedElastic())将这些操作转移到专用的线程池中,以防止阻塞主事件循环线程。
Scheduler 是一个接口,提供了一个抽象层,用于管理线程执行上下文和并发机制。允许开发者灵活地控制响应式管道中不同阶段的执行线程,从而实现高效的非阻塞异步编程。Scheduler调度中,每次线程切换,都会基于选择的 Scheduler 创建一个对应的 Worker 来执行具体的异步任务。Project Reactor 提供了几种主要的 Scheduler 实现,每种都针对特定的工作负载进行了优化:
- Schedulers.immediate(): 在当前调用线程上立即执行任务,避免了不必要的线程切换开销。适用于已是非阻塞的任务。
- Schedulers.single(): 使用一个单一的、可重用的线程,适用于需要按顺序执行任务且不需要并发的场景。
- Schedulers.parallel(): 创建一个固定大小的线程池(通常与 CPU 核心数相等),专为 CPU 密集型、非阻塞的并行计算任务设计。
- Schedulers.boundedElastic(): 这是一个有界限的、弹性的线程池,专为执行阻塞任务(例如 I/O 操作、数据库调用、遗留同步代码)而设计。它会根据需要创建线程,但限制了最大数量,以防止系统资源耗尽。
- Schedulers.fromExecutorService(ExecutorService): 允许将现有的标准 Java ExecutorService 包装成 Scheduler 实例,以便与遗留代码或自定义线程池集成。
Project Reactor提供了 publishOn 和 subscribeOn 两个关键操作符来切换操作符链(pipeline)中的执行上下文:
- subscribeOn():影响其后所有操作符的执行线程,将数据流的处理切换到指定的 Scheduler 管理的线程池。
- publishOn():影响整个响应式链的订阅发生位置(即数据流的源头),但通常在 WebFlux 中,数据流的源头始于 I/O 事件循环线程。
Project Reactor架构将业务逻辑(由 Flux 和 Mono 定义的数据流)与执行策略(线程管理)分离,这使得其具有高度的灵活性和可测试性,同时允许运行时根据任务特性(阻塞 vs. 非阻塞,CPU 密集 vs. I/O 密集)高效利用系统资源。
总结
WebFlux 的线程模型旨在通过事件循环高效处理 I/O 密集型、非阻塞任务,并通过灵活的 Scheduler 机制将任何潜在的阻塞或 CPU 密集型工作卸载到适当的专用线程池,以维护整个系统的响应性和高吞吐量。