Java 响应式编程-Project Reactor基础
概述
在上篇中介绍了响应式编程基础,其中提到在JDK中只提供了接口规范,并没有提供丰富的操作算子。而 Project Reactor就是基于Reactive Streams规范的具体实现。Project Reactor是由 Spring 团队维护的,与 Spring 生态系统(特别是 Spring WebFlux)无缝集成,其专注于高性能的服务器端应用,特别强调与函数式编程和响应式流规范的集成。
Project Reactor基础
Reactor 项目主要是 reactor-core,这是一个基于 Java 8 的实现了响应式流规范 (Reactive Streams specification)的响应式库。Reactor 围绕两个核心发布者(Publisher)实现及其管理订阅和调度的机制展开:
Flux<T>:0到N个元素的异步序列:可以发出零个、一个或多个元素,最后可以发出一个完成信号或一个错误信号。用于处理数据流、事件序列、列表数据等,例如网络请求返回的多个结果。Mono<T>:0到1个元素的异步序列,最多发出一个元素,最后可以发出一个完成信号或一个错误信号。用于处理单个结果的异步操作,例如根据 ID 查找单个用户、执行一个 void 方法(返回 Mono)等。- Scheduler:线程调度器,类似于 RxJava 的 Scheduler,用于管理执行上下文和线程切换。
- Schedulers.elastic():动态线程池,适合 IO 任务。
- Schedulers.parallel():固定大小线程池,适合计算任务。
- publishOn()/subscribeOn():用于控制操作符链的执行线程。
- Subscriber:订阅者/消费者,遵循 Reactive Streams 规范的标准接口,用于消费 Flux 或 Mono 发出的数据。onSubscribe(), onNext(), onError(), onComplete(), request() (背压控制)。
- Publisher:发布者/数据源,Flux 和 Mono 实现的标准接口,定义了 subscribe(Subscriber s) 方法。这是响应式流规范的核心接口,代表可以发出元素和信号的数据源。
在 Reactor 中,当创建了一条 Publisher 处理链,数据还不会开始生成。事实上是创建了一个抽象的对于异步处理流程的描述。只有真正“订阅(subscrib)”的时,将 Publisher 关联到一个 Subscriber 上,才会触发整个链的流动。这时候,Subscriber 会向上游发送一个 request 信号,一直到达源头的 Publisher。
Flux与Mono组件
Flux 是一个发出(emit)0-N个元素组成的异步序列的Publisher<T>, 可以被onComplete信号或者onError信号所终止。一个 flux 的可能结果是一个 value、completion 或 error,就像在响应式流规范中规定的那样,这三种类型的信号被翻译为面向下游的 onNext,onComplete和onError方法。需要注意,所有的信号事件, 包括代表终止的信号事件都是可选的:如果没有 onNext 事件但是有一个 onComplete 事件, 那么发出的就是 空的 有限序列,但是去掉 onComplete 那么得到的就是一个 无限的 空序列。
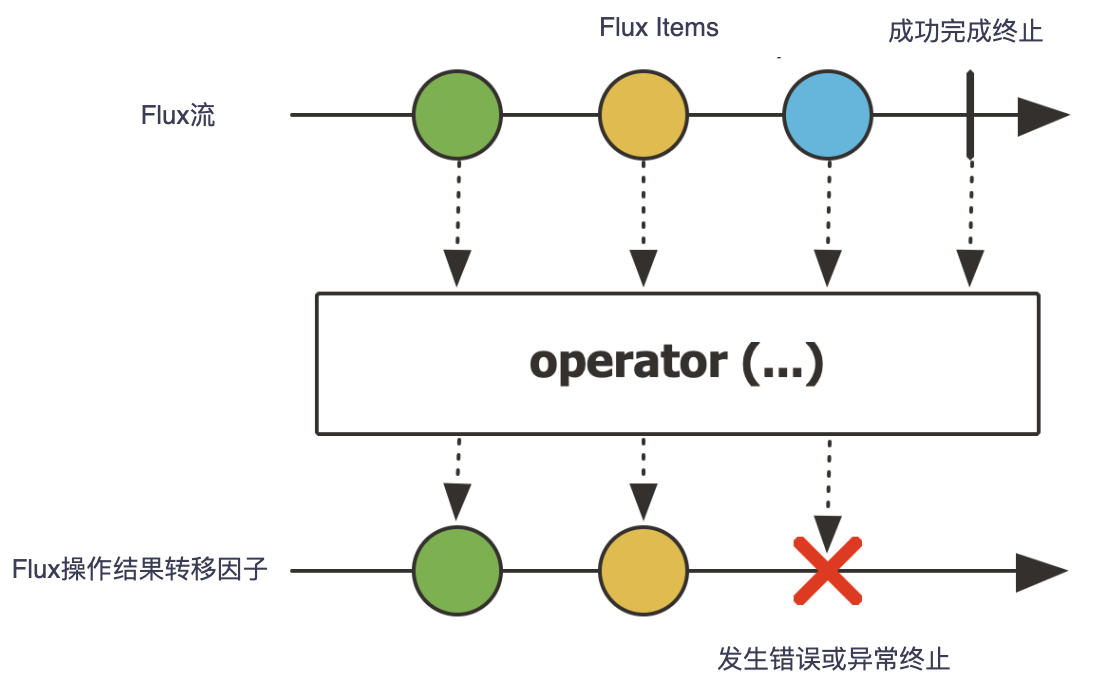
1 | |
Flux常用操作符:
- just():可以指定序列中包含的全部元素。创建出来的Flux序列在发布这些元素之后会自动结束
- fromArray(),fromIterable(),fromStream():可以从一个数组,Iterable对象或Stream对象中穿件Flux对象
- empty():创建一个不包含任何元素,只发布结束消息的序列
- error(Throwable error):创建一个只包含错误消息的序列
- never():传建一个不包含任务消息通知的序列
- range(int start, int count):创建包含从start起始的count个数量的Integer对象的序列
- interval(Duration period)和interval(Duration delay, Duration period):创建一个包含了从0开始递增的Long对象的序列。其中包含的元素按照指定的间隔来发布。除了间隔时间之外,还可以指定起始元素发布之前的延迟时间
- intervalMillis(long period)和intervalMillis(long delay, long period):与interval()方法相同,但该方法通过毫秒数来指定时间间隔和延迟时间
Mono<T> 是一种特殊的 Publisher<T>, 它最多发出一个元素,然后终止于一个 onComplete 信号或一个 onError 信号。它只适用其中一部分可用于 Flux 的操作。比如,(两个 Mono 的)结合类操作可以忽略其中之一 而发出另一个 Mono,也可以将两个都发出,对于后一种情况会切换为一个 Flux。例如,Mono#concatWith(Publisher) 返回一个 Flux,而 Mono#then(Mono) 返回另一个 Mono。注意,Mono 可以用于表示“空”的只有完成概念的异步处理(比如 Runnable)。这种用 Mono<Void> 来创建。
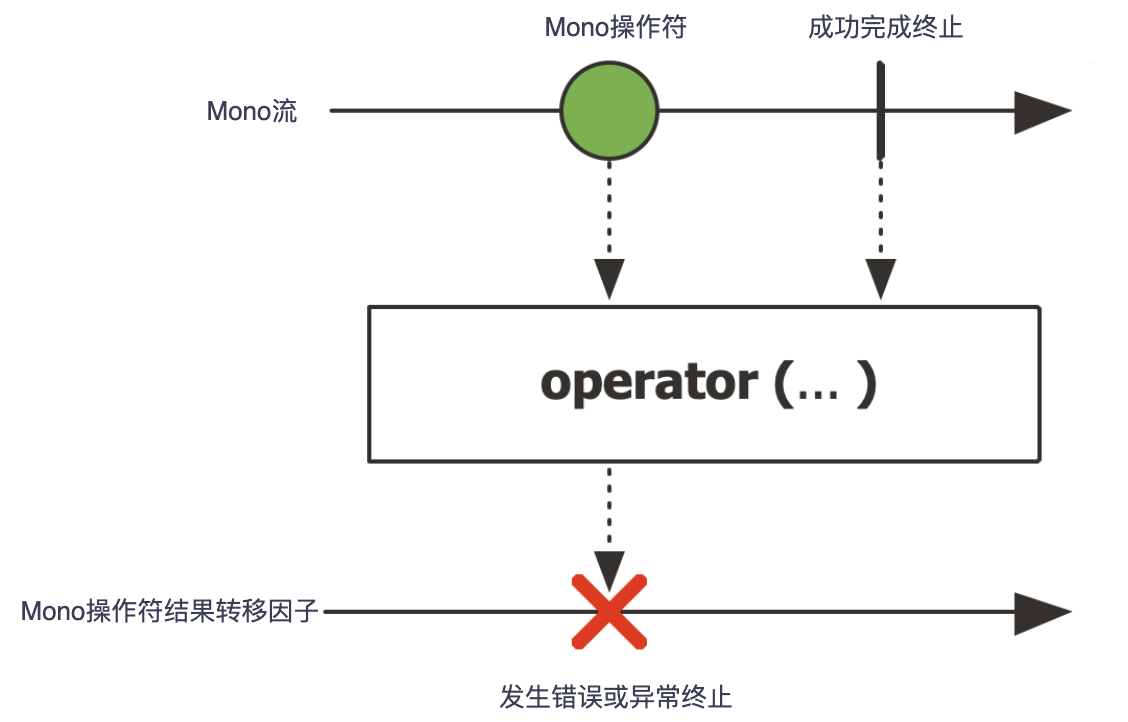
1 | |
Mono常用操作符:Mono类包含了与Flux类中相同的静态方法just(),empty()和never()等。Mono还有一些独有的静态方法:
- fromCallable(),fromCompletionStage(),fromFuture(),fromRunnable()和fromSupplier():分别从Callable,CompletionStage,CompletableFuture,Runnable和Supplier中创建Mono。
- delay(Duration duration)和delayMillis(long duration):创建一个Mono序列,在指定的延迟时间之后,产生数字0作为唯一值。
- ignoreElements(Publisher
source):创建一个Mono序列,忽略作为源的Publisher中的所有元素,只产生消息。 - justOrEmpty(Optional<? extends T> data)和justOrEmpty(T data):从一个Optional对象或可能为null的对象中创建Mono。只有Optional对象中包含之或对象不为null时,Mono序列才产生对应的元素。
Backpressure处理:
1 | |
使用BaseSubscriber实现精细化流量控制(背压,Backpressure),通过重写 hookOnSubscribe 和 hookOnNext 方法,可以手动管理从发布者(Publisher)请求的数据量,而不是默认请求无限制的数据。
1 | |
BaseSubscriber 实现了 Subscriber 接口,并提供了方便的以 hook 开头的方法供重写。它的核心优势在于允许用户直接调用 request(long n) 方法来向上游发布者发出数据请求,从而避免因消费者处理速度慢而导致的系统过载。默认情况下,如果不重写 hookOnSubscribe 或 hookOnNext,BaseSubscriber 会自动发出一个无限制的请求(Long.MAX_VALUE)。
- hookOnSubscribe(Subscription subscription):这个方法在订阅成功建立时被调用,可以在此方法中执行初始设置,并发出首个数据请求。它是与上游 Subscription 交互的,必须在此处调用 request(long n) 来启动数据流。如果在此处请求有限数量(例如 request(1) 或 request(5)),则意味着需要在 hookOnNext 中继续手动请求后续数据。
- hookOnNext(T value):这个方法在每次接收到上游发出的数据项时被调用,是处理业务逻辑和持续流量控制的地方。在处理完当前接收到的数据后,可以决定何时以及请求多少下一个数据。如果在 hookOnSubscribe 中请求了有限数量,那么为了让数据流继续,需要在 hookOnNext 方法中再次调用 request(long n) 来请求下一个(或下一批)数据。
常用功能操作符
Project Reactor 提供了丰富的操作符来处理 Flux (0到N个元素) 和 Mono (0或1个元素) 数据流。虽然没有一个官方统一的分类标准,但根据功能,可以将这些操作符分为:创建操作符 (Creation Operators)、转换操作符 (Transformation Operators)、过滤操作符 (Filtering Operators)、组合操作符 (Combining Operators)、工具操作符 (Utility/Side-Effect Operators)。
创建操作符 (Creation Operators)
just(T...): 从给定的元素创建一个 Flux 或 Mono。
1 | |
generate():通过同步和逐一的方式来产生Flux序列。序列的产生是通过调用所提供的的SynchronousSink对象的next(),complete()和error(Throwable)方法来完成的。逐一生成的含义是在具体的生成逻辑中,next()方法只能最多被调用一次。
1 | |
create():create 是一种更高级的编程方式创建 Flux 的形式,它适合每轮多次发出,甚至来自多个线程。它暴露了一个 FluxSink 及其 next,error 和 complete 方法。与 generate 相反,它没有基于状态的形式。但是,它可以在回调中触发多线程事件。
1 | |
defer():延迟捕获或创建序列对象。它会在每次对生成的 Flux/Mono 进行订阅时懒惰地提供一个发布者,因此实际的源实例化被推迟到每次订阅时,并且提供者可以创建一个订阅者特定的实例。
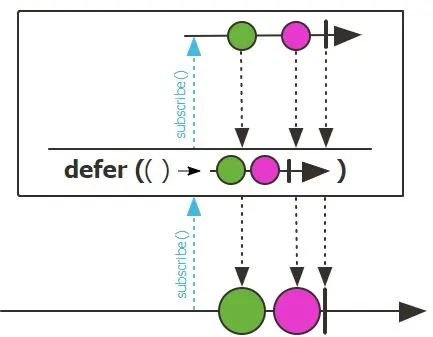
1 | |
fromIterable(Iterable<T>)/fromArray(T[]): 从 Iterable (如 List, Set) 创建一个 Flux。
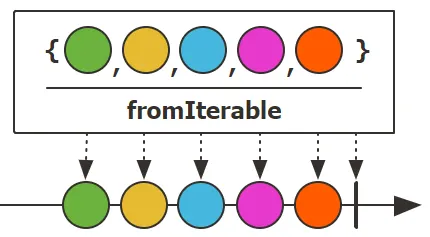
1 | |
fromRunnable(Runnable) / fromCallable(Callable<T>): 将命令式代码转换为 Mono,并在订阅时执行。
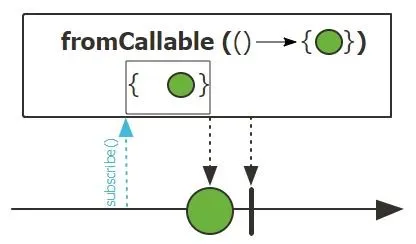
1 | |
fromSupplier():它与 defer() 类似,用于延迟创建类似 Mono 的序列对象。但不同之处在于,它可以自动将提供的数据转换为 Mono 格式。它创建一个 Mono 对象,并使用提供的提供者生成其值,如果提供者解析为 null,则生成的 Mono 对象为空。
1 | |
range(): 创建一个整数序列的 Flux。empty()/defaultIfEmpty(): 创建一个立即完成但没有任何元素的 Flux 或 Mono。
![]()
1 | |
转换操作符 (Transformation Operators)
map(Function<T, V>): 同步地将上游的每个元素映射为下游的一个新元素。
1 | |
flatMap(Function<T, Publisher<V>>): 异步地将每个元素映射为一个新的 Publisher(Mono 或 Flux),并将所有内部流合并为一个扁平的下游流。这是响应式编程中最强大的操作符之一。
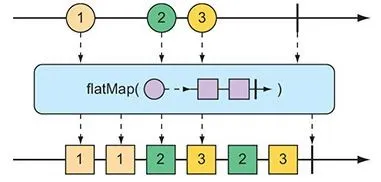
1 | |
buffer(int maxSize) / window(int maxSize): 将元素收集到 List (buffer) 或一个新的 Flux (window) 中,然后发射这些集合。cast(Class<V> clazz): 将流中的元素转换为指定的类型。
过滤操作符 (Filtering Operators)
filter(Predicate<T>): 只允许满足条件的元素通过。
1 | |
take(long n): 只获取前 N 个元素。skip(long n): 跳过前 N 个元素。distinct() / distinctUntilChanged(): 过滤掉重复的元素。
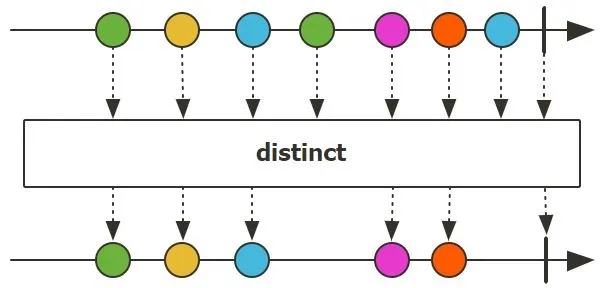
1 | |
组合操作符 (Combining Operators)
merge(Publisher<T>... principals): 以交错的方式合并多个 Publisher 的输出。
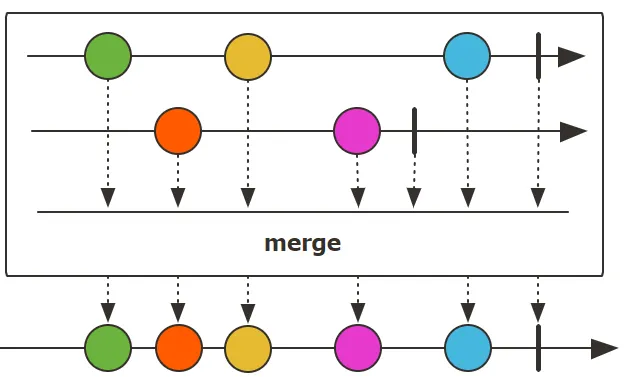
1 | |
zip(Publisher<T> p1, Publisher<V> p2): 将两个源 Publisher 按顺序发射的元素配对组合成一个新的元素(如 Tuple2)。
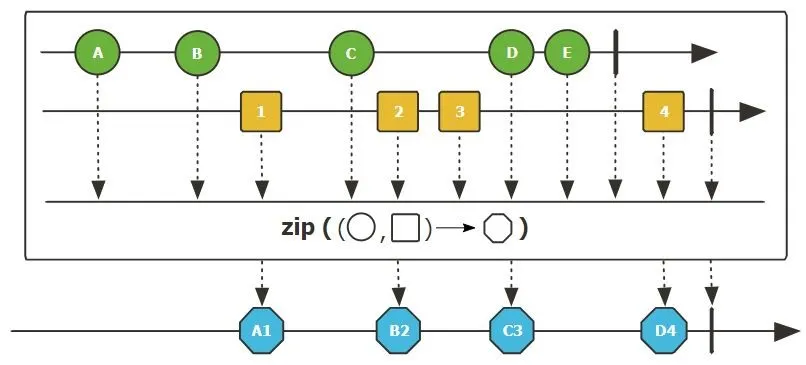
1 | |
concat()/concatMap():将提供的所有源连接成一个可迭代对象,并将源发出的元素向下游转发。concat是通过依次订阅第一个源,然后等待其完成再订阅下一个源来实现的,依此类推,直到最后一个源完成。任何错误都会立即中断序列并向下游转发,它会返回一个新的 Flux,该 Flux 连接了所有源序列。
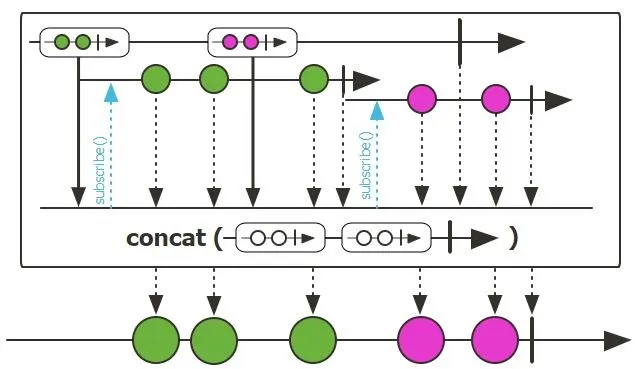
1 | |
then()/thenEmpty():不关心发布者输出了哪些元素,而只关心它何时完成发布的情况。因此,它会接收一个现有的发布者,丢弃它所有的元素,然后传播完成信号或错误信号。如果我们把任何 Mono 作为 then() 的参数传递,它会将该 Mono 作为输出传递。
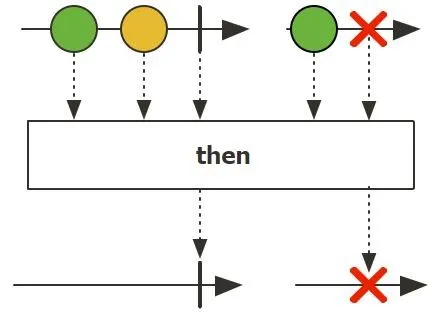
1 | |
工具操作符 (Utility/Side-Effect Operators)
log(): 记录所有响应式信号 (onNext, onError, onComplete, onSubscribe, request) 到日志。doOnNext(...), doOnError(...), doOnComplete(...): 注册回调函数以观察特定信号并执行Side-Effect操作。
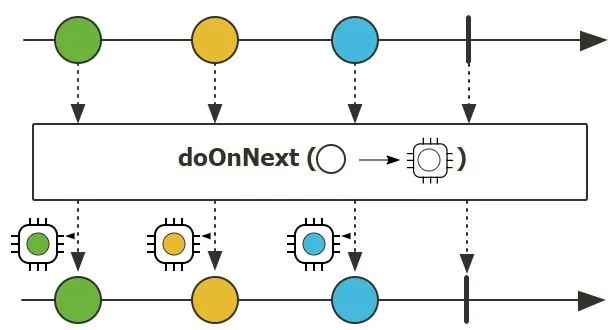
1 | |
subscribeOn(Scheduler s): 指定上游源执行的调度器(线程池)。
1 | |
publishOn(Scheduler s): 指定下游操作符执行的调度器。
1 | |
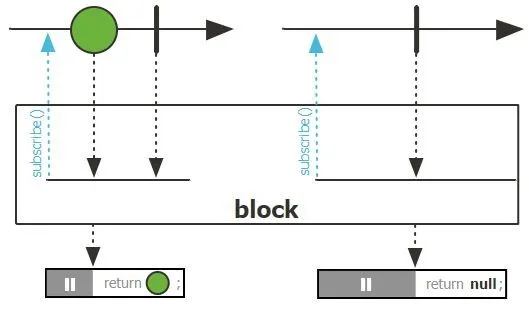
block() / blockFirst() / blockLast(): 阻塞当前线程直到流完成或发出元素(应谨慎使用,主要用于测试或非响应式边界)。
1 | |
switchIfEmpty():如果序列完成时没有任何数据,它会切换到备用发布者。
![]()
1 | |
handle():用于创建自定义处理器。handle 方法可以用于自定义流的处理逻辑,与 map 方法重新映射、生成新的流不同,handle 方法用于消费元素,可以重新定义流。
1 | |
错误处理
在 Project Reactor 中,处理错误是响应式编程的关键部分,流一旦发生错误就会终止 (onError 信号),因此需要使用特定的操作符来截取错误并决定后续行为。
错误恢复操作符 (Recovery Operators):
onErrorReturn(T fallbackValue):当发生错误时,抛出一个默认值,然后正常完成 (onComplete)。适用于需要提供一个默认值作为简单回退逻辑的情况,例如:服务不可用时返回一个缓存的默认值。
1 | |
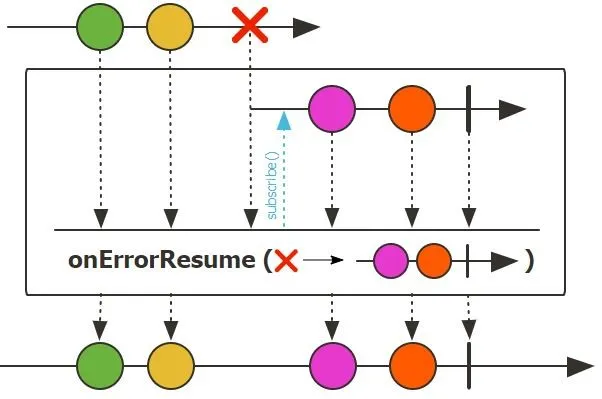
onErrorResume(Function<Throwable, ? extends Publisher<? extends T>> fallbackSupplier):当发生错误时,切换到一个新的备用 Publisher (如另一个 Mono 或 Flux) 来继续数据流。适用于需要执行更复杂的备用逻辑、调用另一个服务或根据错误类型动态生成备用数据流的情况。
1 | |
onErrorComplete():捕获错误信号,并将其转换为正常的完成信号 (onComplete)。适用于成功的结果而可以完全忽略错误的场景。
1 | |
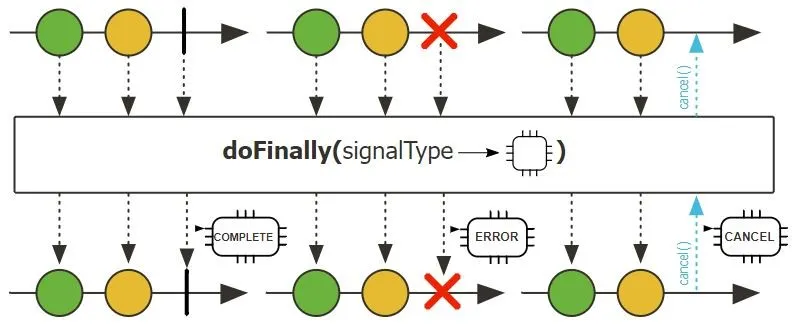
doFinally():最终执行,类似try-finally。 doFinally 在终止时无论是 onComplete、onError还是取消都会被执行, 并且能够判断是什么类型的终止事件。
1 | |
onErrorContinue(BiConsumer<Throwable, Object> consumer):允许在处理 Flux 流中的元素时,跳过导致错误的元素,记录错误信息,然后继续处理流中的下一个元素。主要用于 Flux 中,当某个元素处理失败不应中断整个流时。注意,必须将此操作符放在可能抛出异常的操作符(例如 map)之前。
错误转换操作符
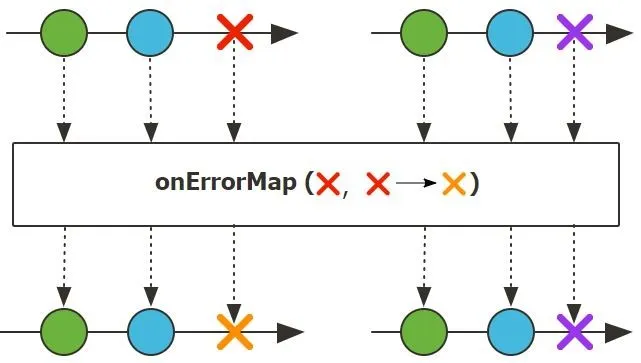
onErrorMap(Function<Throwable, Throwable> mapper):将捕获到的异常转换为另一种自定义的异常类型,并重新抛出(向下游传递新的 onError 信号)。适用于将底层技术异常(如 IOException)封装为业务异常(如 UserServiceException),以便下游更好地理解和处理。
1 | |
doOnError(Consumer<Throwable> consumer):注册一个回调函数,用于观察(记录日志、监控指标等)错误信号,但不会改变或消耗错误信号,错误会继续向下游传播。仅用于执行副作用操作,如日志记录或指标收集。
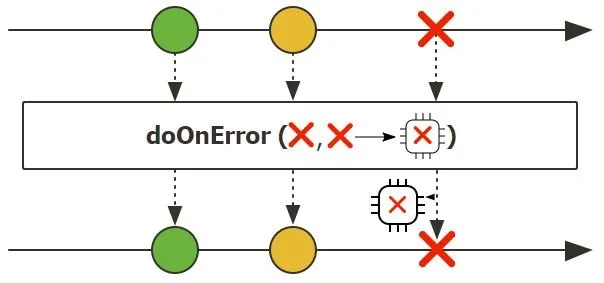
1 | |
重试操作符 (Retry Operators)
retry() 或 retry(long maxRetries):发生错误时,重新订阅上游的 Publisher,尝试再次执行整个流。原始流会终止,但 retry 会创建一个新的订阅。适用于处理瞬时错误(例如网络波动、临时服务不可用)的情况。应设置最大重试次数以避免无限循环。
1 | |
retryWhen(Function<Flux<Throwable>, ? extends Publisher<?>>):: 提供基于异常类型和重试次数的更精细的重试逻辑控制,支持指数退避等高级策略。
1 | |
线程和调度器
响应式流(Flux和Mono)本质上是关于数据流和信号回调的,而不是并发模型。默认情况下,操作符会继续在执行前一个操作符的线程中工作。即,除非指定,否则源操作符本身运行在调用了 subscribe() 的 Thread 上。
1 | |
Reactor的 调度器(Scheduler) 是控制线程执行的关键机制,它类似于 ExecutorService,用于将不同的操作分派到特定的线程或线程池。Schedulers 类提供了一系列静态方法来访问不同类型的内置调度器,它们抽象了底层的线程池管理。Reactor主要的内置调度器类型包括:
- Schedulers.immediate(): 在当前线程中立即执行任务。
- Schedulers.single(): 使用一个单一的、可重用的后台线程。
- Schedulers.parallel(): 使用一个固定大小的线程池,其大小通常等于 CPU 核心数,适用于并行计算任务。
- Schedulers.boundedElastic(): 这是一个有界的弹性线程池,按需动态创建线程,但有数量上限,适用于执行阻塞 I/O 操作(如数据库调用、网络请求)。它是已弃用的 Schedulers.elastic() 的替代品。
除了上面内置的调度器,也可以使用现有的 ExecutorService 创建自定义调度器。Project Reactor 提供了两个核心操作符来控制流的执行线程上下文:
- subscribeOn(Scheduler):把订阅动作(Subscriber.onSubscribe 的创建、链路建立、上游 request 的初次调用等)移动到指定 Scheduler。当在上游调用 subscribe 时,subscribeOn 会 schedule 一个 Runnable 去执行真正的 subscribe 操作(即把 subscription 的建立放到其他线程),因此上游的同步产生/拉取代码会在该 Scheduler 的线程上运行。它影响整个操作链的源头(upstream)和下游(downstream),决定了数据生成和初始订阅发生的线程。无论 subscribeOn 放在操作链的哪个位置,它都会改变整个流的根执行上下文。
- publishOn(Scheduler):在数据流中的某处建立异步边界——把从这个 operator 向下游发送的信号切换到指定 Scheduler 的线程。publishOn 用一个内部队列把上游发来的 onNext/onError/onComplete 等事件缓存起来,然后在 Worker 的线程中做 drain(取出并调用下游的 onNext/onComplete/onError)。因此,publishOn 会序列化并且切换信号执行线程。它只影响其 下游(downstream) 的操作符(从它出现的位置到下一个 publishOn 或流结束)。会在流中引入一个异步边界,将后续的处理切换到指定的调度器上。这对于在不同阶段(例如,将 I/O 操作与 CPU 密集型操作分开)使用不同的线程池非常有用。
1 | |