Java 响应式编程基础
概述
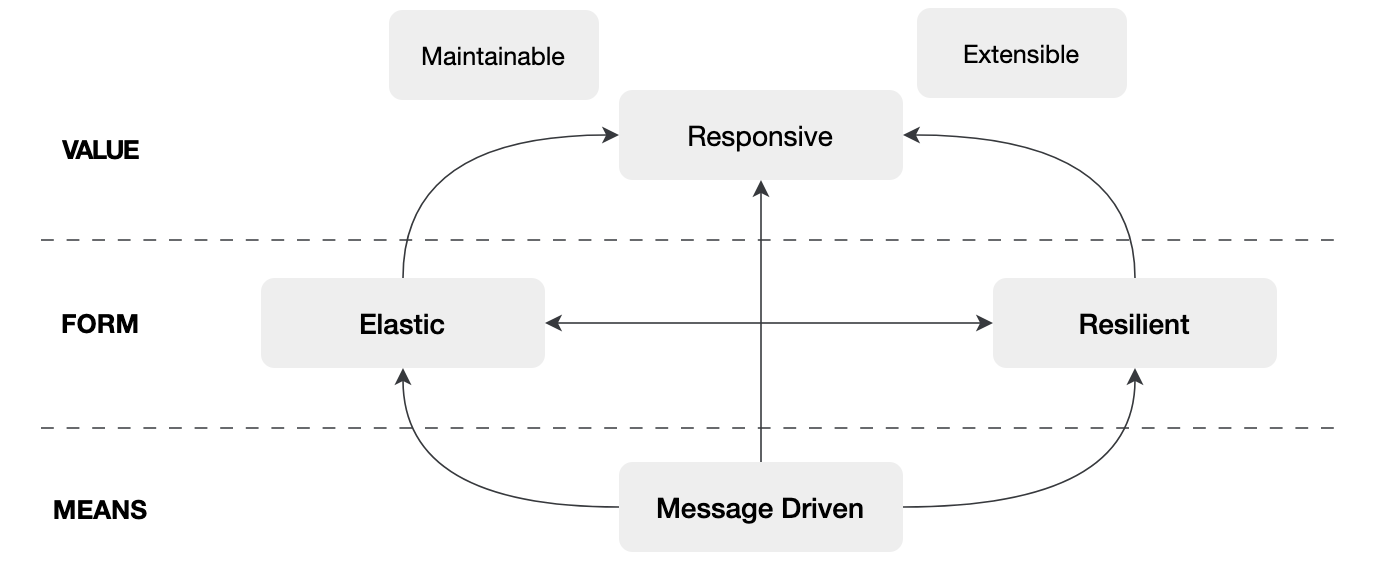
响应式编程(Reactive Programming)是 2013 年底由 Netflix、Lightbend 和 Pivotal(Spring 背后的公司)的工程师发起的一项计划,是一种处理异步数据流并传播变化的编程范式,旨在构建更具响应性、弹性、可伸缩性的非阻塞式应用。它主要围绕数据流和变化的自动传播来构建,核心在于对事件作出反应。 2015 年 Reactive Stream(响应式流)规范诞生,为 JVM 上的响应式编程定义了一组接口和交互规则。根据反应式编程规范,反应式系统具有以下特征:
- 响应迅速:一个响应式系统应该提供快速且一致的响应时间,从而提供一致的服务质量。
- 高可用:反应式系统应通过复制和隔离,在发生随机故障时保持响应能力。
- 可扩展:这样的系统应该能够通过经济高效的可扩展性,在不可预测的工作负载下保持响应能力。
- 消息驱动:应该依赖于系统组件之间的异步消息传递。
响应式模型有两种基本的实现机制:
- 一种就是传统开发模式下的“拉”模式,即消费者主动从生产者拉取元素;
- 一种是“推”模式,在这种模式下,生产者将元素推送给消费者。相较于“拉”模式,“推”模式下的数据处理的资源利用率更好。
推模式中数据流的生产者会持续地生成数据并推送给消费者。这里就引出了 流量控制问题 ,即如果数据的生产者和消费者处理数据的速度是不一致的。当生产者和消费者处理数据的速度不一致有如下两种情况:
- 生产者生产数据的速率小于消费者的场景: 这种场景对于消费者来说没啥压力,正常消费就好了,这里也就不需要所谓的流量控制了。
- 生产者生产数据的速率大于消费者的场景: 生产者生产数据的速率大于消费者的场景,应该是我们业务中经常遇到的场景了,这种场景由于消费者处理不过来导致崩溃,业界通常的做法是在生产者与消费者之间加一个队列做缓冲。我们知道队列具有存储与转发的功能,所以可以用它来进行一定的流量控制。
控制流量主要基于 Java 的队列实现,主要有以下三种实现方式:
无界队列:无界队列在原则上是拥有无线大小容量的队列,可以存放生产者产生的所有消息。
- 优势:确保消费者消费到所有的数据
- 劣势:系统的回弹性降低,任何一个系统不可能拥有无限的资源,一旦内存等资源耗尽,系统就可能会有崩溃的风险。
有界丢弃队列:为了避免上面无界队列的弊端,有界丢弃队列采用的是如果队列满了,就会采用丢弃后面传入的值,这里可以设置一些丢弃策略,比如说按照优先级或先进先出等。
- 优势:考虑到资源的限制,适合允许丢消息的业务场景。
- 劣势:消息重要性很高的场景不建议采取这种队列
有界阻塞队列:在数据高度一致性的场景是不允许丢数据的,这时使用有界阻塞队列,当队列消息数量达到上限后阻塞生产者,而不是直接丢弃消息。
- 优势:解决了不允许丢数据的业务场景
- 劣势:当队列满了的时候,会阻塞生产者停止生产数据,这种场景不可能实现异步操作的。
在推模式下的数据流量会有很多不可控制的因素,并不能直接应用,而是需要在“推”模式和“拉”模式之间考虑一定的平衡性,从而优雅地实现流量控制。这就需要引出响应式系统中非常重要的一个概念——背压机制(Backpressure)。 背压机制是指下游能够向上游反馈流量请求的机制。采用背压机制,消费者会根据自身的处理能力来请求数据,而生产者也会根据消费者的能力来生产数据,从而在两者之间达成一种动态的平衡,确保系统的即时响应性。
Reactive Stream实现
前面提到,2015 年 Reactive Stream(响应式流)规范正式发布,Java 9 正式引入了响应式编程的 API,将 Reactive Stream 规范定义的四个接口集成到了 java.util.concurrent.Flow 类中,Java 9 Flow 提供了一个标准化的基础接口:
1 | |
在实际应用中,Java Reactive Stream 有多种具体实现,最常用的是:
- Java 9 Flow API:Java 9 Flow 提供了一个标准化的基础接口,定义了响应式流应该如何工作,但不提供具体的实现或操作符。它旨在确保不同的响应式库(如 RxJava 和 Reactor)能够相互协作(互操作性)。
- Project Reactor:是由 Spring 团队维护的,与 Spring 生态系统(特别是 Spring WebFlux)无缝集成,专注于高性能的服务器端应用。
- RxJava: 是一个更通用的库,提供了更丰富的操作符和类型(如 Single, Completable),在 Android 和各种独立 Java 应用中非常流行。
- Akka Streams:提供了直观、类型安全且支持背压的流处理 API,其核心功能是使用有限的缓冲区资源高效执行流式计算。
Project Reactor
Project Reactor 的核心功能专注于构建高效、非阻塞的服务器端应用程序,特别强调与函数式编程和响应式流规范的集成。其核心在于使用 Flux 和 Mono 这两个核心类型来处理数据流。核心功能如下:
- 响应式流规范实现:Reactor 完全实现了 Reactive Streams 规范,确保了良好的互操作性和标准的背压(Backpressure)支持。
- 函数式与声明式 API:Reactor 的 API 设计高度函数式,利用 Java 8 的 Lambda 表达式,使得数据转换和组合操作非常简洁易读。
- 与 Spring 生态集成:这是 Reactor 的关键优势。它是 Spring WebFlux 的基础,使得构建完全响应式的 Spring 5+ 应用成为可能。
- 简化的类型系统:相比 RxJava 复杂的类型(如 Observable, Flowable, Single, 等),Reactor 仅使用 Flux(0到N个元素)和 Mono(0到1个元素)来覆盖所有场景,降低了学习和使用的复杂性。
- 高效的背压管理:通过 Reactive Streams 接口,Reactor 能够自动管理生产者和消费者之间的需求信号,有效控制资源使用。
Reactor 围绕两个核心发布者(Publisher)实现及其管理订阅和调度的机制展开:
Flux<T>:0到N个元素的异步序列:可以发出零个、一个或多个元素,最后可以发出一个完成信号或一个错误信号。用于处理数据流、事件序列、列表数据等,例如网络请求返回的多个结果。Mono<T>: 0到1个元素的异步序列,最多发出一个元素,最后可以发出一个完成信号或一个错误信号。用于处理单个结果的异步操作,例如根据 ID 查找单个用户、执行一个 void 方法(返回 Mono)等。 Scheduler:线程调度器,类似于 RxJava 的 Scheduler,用于管理执行上下文和线程切换。- Schedulers.elastic(): 动态线程池,适合 IO 任务。
- Schedulers.parallel(): 固定大小线程池,适合计算任务。
- publishOn() / subscribeOn(): 用于控制操作符链的执行线程。
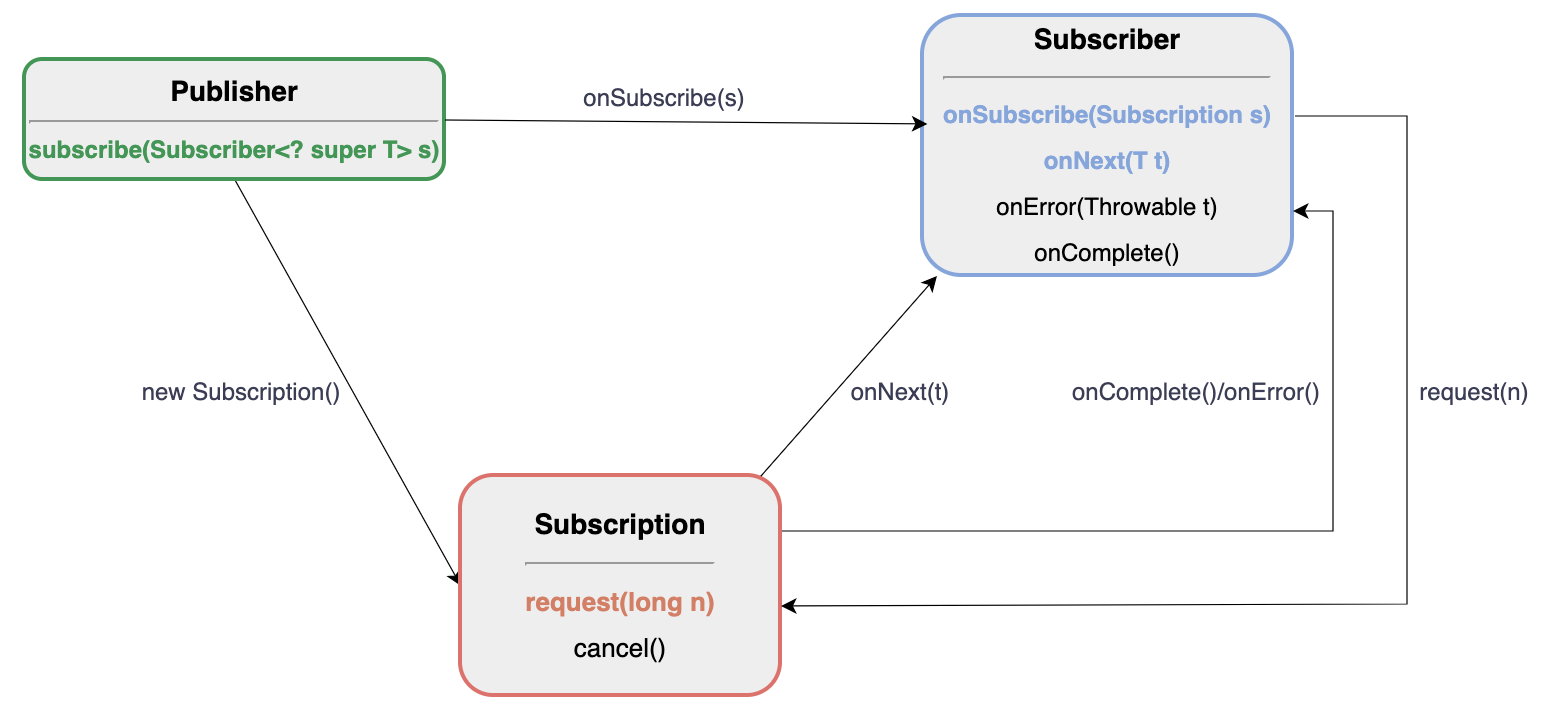
Subscriber:订阅者/消费者,遵循 Reactive Streams 规范的标准接口,用于消费 Flux 或 Mono 发出的数据。onSubscribe(), onNext(), onError(), onComplete(), request() (背压控制)。Publisher: 发布者/数据源,Flux 和 Mono 实现的标准接口,定义了 subscribe(Subscriber s) 方法。这是响应式流规范的核心接口,代表可以发出元素和信号的数据源。
RxJava
RxJava 的核心功能在于使用可观察序列(observable sequences)来组合异步和基于事件的程序,它将扩展的观察者模式(Observer pattern)应用于数据流和事件流。其核心功能主要围绕四个基本组件及其提供的丰富操作符。
- 异步编程与事件处理:RxJava 提供了一种优雅的方式来处理异步操作(如网络请求、数据库查询、用户界面事件),避免了传统回调嵌套导致的“回调地狱”(Callback Hell)。
- 链式调用与操作符:RxJava 提供了数百种强大的操作符(Operators),允许开发者以声明式的方式组合、转换、过滤和合并数据流。这些操作符支持流畅的链式调用,使复杂的业务逻辑清晰易懂。
- 线程调度(Schedulers):RxJava 抽象了线程管理,通过 Schedulers 组件,开发者可以轻松地指定代码运行的线程(例如,在 IO 线程执行耗时操作,在主线程更新 UI),从而简化并发编程。
- 背压支持(Backpressure):针对可能产生大量数据的场景(数据生成速度快于消费速度),RxJava 引入了背压机制,允许消费者控制数据源的发送速度,防止系统过载。
RxJava 的核心概念主要由以下四个基本接口(或类)构成:
Observable / Flowable:发出数据或事件的序列。Flowable 专用于支持背压的场景,subscribe(Observer)将观察者与被观察者连接起来。
Observer / Subscriber:观察者/消费者,接收并处理 Observable 或 Flowable 发出的数据或事件。
- onNext(T t): 接收下一个数据项。
- onError(Throwable e): 接收错误通知。
- onComplete(): 接收完成通知(无更多数据)。
- onSubscribe(Disposable d): 建立订阅关系时调用。
Disposable:可处置对象,表示一个订阅关系,用于在不需要继续接收数据时取消订阅,防止内存泄漏。
- dispose(): 取消订阅。
- isDisposed(): 检查是否已取消。
Scheduler:线程调度器,管理操作符和订阅执行的线程上下文。
- Schedulers.io(): 用于 IO 密集型任务。
- AndroidSchedulers.mainThread(): 在 Android 主线程执行 UI 操作。
Single, Maybe, Completable:针对特定场景的简化版数据源。
- Single 只发射一个数据或一个错误;
- Completable 只发射完成信号或错误;
- Maybe 可发射零个或一个数据,以及完成信号或错误。
Akka Streams
Akka Streams建立在强大的 Akka Actor 模型之上,但提供了一个更高级别的抽象,使得开发者无需手动管理底层的背压信号。其核心功能:
- 非阻塞背压(Non-Blocking Backpressure):Akka Streams 完全实现了 Reactive Streams 规范,这是其最核心的功能。数据发送方会根据接收方的处理能力自动调整发送速率,防止资源耗尽或内存溢出。
- 有界资源使用(Bounded Resource Usage):流处理的实体只缓冲有限数量的元素。即使在重负载或高流量输入下,也能确保有界的内存使用,这是它与传统 Actor 模型的一个关键区别。
- 声明式 API 与图形 DSL:Akka Streams 提供了流畅的、声明式的领域特定语言(DSL),允许开发者以非常直观的方式描述数据流的拓扑结构(即流经的路径),类似于构建一个计算图(Graph)。
- 物化(Materialization):流的定义(蓝图)本身只是一个描述,必须通过“物化”步骤才能真正运行。物化过程将逻辑流描述转换为正在运行的 Actor 链,并在此过程中处理线程调度和优化(如熔合 Fusing)。
- 与 Akka 生态集成:可以方便地与 Akka Actors、Akka HTTP、Akka Kafka 连接器等其他 Akka 模块集成,用于构建完整的分布式、容错系统。
虽然 Akka Streams 在内部使用 Reactive Streams 接口,但提供给最终用户的 API 是高度抽象的三个核心组件,用于构建任何线性的流处理管道:
Source<Out, Mat>:数据源(Publisher),具有一个输出端口,负责产生数据流的起点。数据可以来自集合、文件、Actor 或其他系统。 对应JDK中Publisher。Flow<In, Out, Mat>:数据转换(Processor),具有一个输入端口和一个输出端口,用于在数据流经过程中进行转换、过滤、映射、聚合等操作。 对应JDK中Processor。Sink<In, Mat>:数据终点(Subscriber),具有一个输入端口,负责消费数据流的终点,例如写入文件、发送给 Actor 或返回单个聚合结果。对应JDK中Subscriber。
此外,还有两个核心接口:
- RunnableGraph:当 Source、Flow 和 Sink 被连接成一个完整的、封闭的拓扑结构时,就形成了一个可运行的图(Runnable Graph)。调用其 .run(materializer) 方法即可启动流处理。
- Materializer:这是一个至关重要的组件,负责将抽象的 RunnableGraph 转换为实际运行的流处理器实例(由 Akka Actors 支持)。
RxJava、Project Reactor、Java 9 Flow区别
RxJava、Project Reactor 和 Java 9 Flow API 的主要区别在于它们的定位、功能丰富度以及与特定生态系统的集成。Java 9 Flow 提供了一个标准化的基础接口,而 RxJava 和 Project Reactor 则是功能更全面的实现库,提供了丰富的操作符和实用工具。
| 特性 | Java 9 Flow | Project Reactor | RxJava |
|---|---|---|---|
| 定位 | JDK 内置的 响应式流(Reactive Streams)规范 接口。 | 一个功能齐全的响应式编程库。 | ReactiveX 规范的 Java 实现库。 |
| 功能 | 仅包含基础接口 (Publisher, Subscriber, Subscription, Processor),没有具体实现或操作符。 |
拥有丰富的操作符和调试工具,提供 Flux (0..N 个元素) 和 Mono (0..1 个元素) 核心类型。 |
拥有数百种操作符,提供 Flowable (支持背压), Observable, Single, Completable, Maybe 等多种类型。 |
| 背压 (Backpressure) | 作为规范的一部分,要求实现支持背压机制。 | 完全支持背压,是其核心特性之一。 | Flowable 类专门用于处理支持背压的数据流。 |
| 主要用途/生态 | 作为其他响应式库互操作性的基础标准。 | 与 Spring WebFlux 紧密集成,常用于构建响应式微服务和非阻塞 API。 | 广泛应用于 Android 开发和通用的事件驱动架构。 |
| 学习曲线 | 简单,因为它只是几个接口。 | 学习曲线中等,操作符丰富,但有良好的文档和调试支持。 | 学习曲线较陡峭,概念和操作符众多。 |
jdk Flow
Java Flow API 的设计初衷是提供一个标准化的接口规范,而不是一个完整的终端用户库(如 RxJava 或 Project Reactor)。因此,JDK 默认不包含丰富的实现类或操作符。它的主要作用是作为不同响应式库之间的互操作性标准,使它们能够无缝协作。 Java Flow API 包含在 java.util.concurrent.Flow 类中,由四个静态嵌套接口组成:
Flow.Publisher<T>:发布者(数据源),负责生产数据流并将其发送给已订阅的 Subscriber。它只包含一个方法 subscribe(Subscriber<? super T> subscriber)。Flow.Subscriber<T>:订阅者(消费者),负责消费 Publisher 发出的数据。它定义了四个生命周期方法:onSubscribe, onNext, onError, onComplete。Flow.Subscription:上下文,代表 Publisher 和 Subscriber 之间的连接,用于管理背压(backpressure)。它有两个关键方法:request(long n)(订阅者请求数据)和 cancel()(取消订阅)。Flow.Processor<T, R>:处理器,兼具 Subscriber 和 Publisher 的双重角色,用于在流中进行数据转换(例如,从类型 T 转换为类型 R)。
在标准的 JDK 中,Java 9 Flow API 仅提供了一个具体的、开箱即用的 Publisher 实现类:
1 | |
JDK Flow使用示例
需要自定义实现:Subscriber与Processor
1 | |