概述
Disruptor是LMAX公司开发的一个高性能的有界内存队列,其目的是为了解决内存队列的延迟问题。目前应用非常广泛,Log4j2、Spring Messaging、HBase、Storm等都有使用到Disruptor。Disruptor项目团队的一篇论文,其高性能总结如下:
- 高效数据结构—环形缓冲区(RingBuffer):环形缓冲区(Ring Buffer)是一个预先分配好内存空间的固定大小的数组,数组元素在初始化时一次性全部创建。使用数组而非链表结构,是为了避免频繁创建和销毁节点带来的垃圾回收(GC)开销,从而降低延迟。并且数组在内存中是连续存放的,这对 CPU 的缓存机制(缓存行)非常友好,可以提高数据访问效率。环形缓冲区定义大小必须是 2 的 N 次幂,这样做的好处是可以通过位运算(index & (bufferSize - 1))快速定位数组下标,省去了昂贵的取模运算。
- 并发控制—无锁设计(Sequencer 和 Sequence Barrier):Disruptor 采用无锁或极少锁的设计来管理并发访问,替代传统的锁和阻塞队列机制。 生产者和消费者都维护一个独立的序列号,表示当前处理到的位置。通过比较序列号来判断是否有新的事件可用或是否有足够的空间写入。序列栅栏(Sequence Barrier)负责协调生产者和消费者之间的序列号,确保消费者不会读取到尚未写入的事件,生产者也不会覆盖尚未消费的事件。在多生产者场景下,使用 Compare-And-Swap (CAS) 原子操作来竞争下一个可写的序列号,避免使用重量级锁。
- 性能优化—消除伪共享(Padding):为了进一步优化性能,Disruptor 使用 缓存行填充(Cache Line Padding) 技术来消除伪共享(False Sharing)问题。 伪共享是当多个线程操作不同但位于同一个 CPU 缓存行的数据时,会导致缓存行的频繁失效和同步,降低性能。Disruptor 在关键变量(如序列号)前后填充额外的字节,确保它们位于独立的缓存行中,从而避免不必要的缓存同步。
- 事件处理—预分配与等待策略:
- 缓冲区中的“事件”(Event,即数据对象)是预先创建好的普通 Java 对象。生产者只需更新对象的内容,而不需要在每次生产数据时都创建新对象,进一步减少 GC 开销。
- 消费者可以通过不同的等待策略来决定如何等待新事件的到来(例如,忙等待、带超时等待、阻塞等待等),以平衡 CPU 利用率和延迟。
总之:Disruptor 在实现上通过结合环形数组、无锁并发控制(序列号和 CAS)、缓存行优化和内存预分配等多种底层技术,构建了一个高效的生产者-消费者框架,能够在线程间数据交换时提供远超传统阻塞队列的性能。
架构
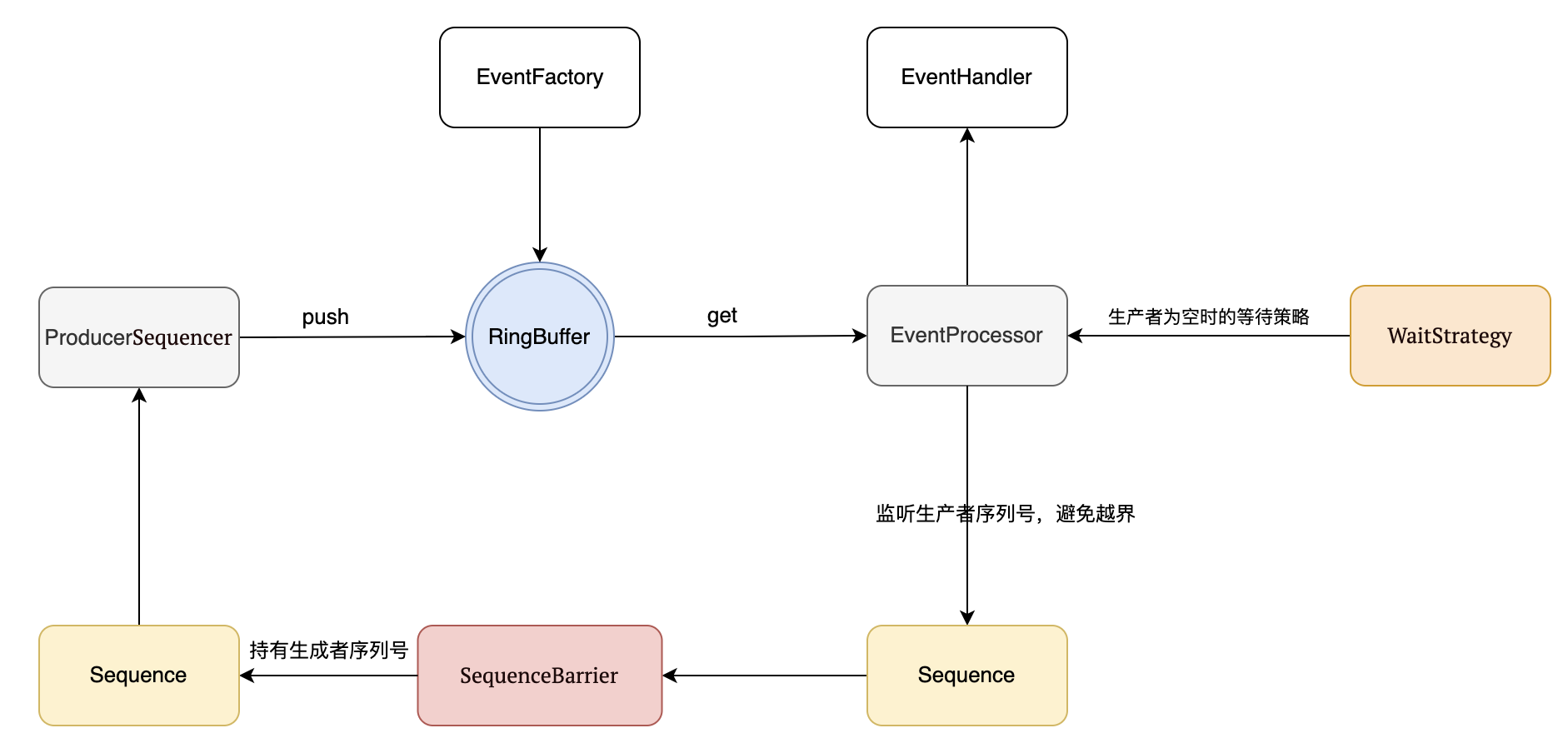
Disruptor 框架主要由以下几个核心组件构成,它们共同协作实现了高效的线程间数据交换。
- Ring Buffer(环形缓冲区):环形缓冲区通常被视为 Disruptor 的核心组件。
- Sequencer:(序号管理器)。序列器是 Disruptor 的核心部分。这个接口有两个实现(单生产者和多生产者),它实现了所有并发算法,用于在生产者和消费者之间快速、正确地传递数据。
- Sequence(序列):Disruptor 使用序列(Sequence)来标识某个特定组件的进度。每个消费者(事件处理器)以及 Disruptor 本身都会维护一个序列。主要是为了解决并发冲突,disruptor里面大部分的并发代码都是通过对Sequence的值同步修改实现的,而非锁,类似于AtomicLong,但是解决了伪共享问题,这是disruptor高性能的一个主要原因。
- SequenceBarrier(序号栅栏):,管理和协调生产者的游标序号和各个消费者的序号,确保生产者不会覆盖消费者未来得及处理的消息,确保存在依赖的消费者之间能够按照正确的顺序处理。
- EventProcessor(事件处理器):监听RingBuffer的事件,并消费可用事件,从RingBuffer读取的事件会交由实际的生产者实现类来消费;它会一直侦听下一个可用的序号,直到该序号对应的事件已经准备好。
- EventHandler(业务处理器):是实际消费者的接口,完成具体的业务逻辑实现,第三方实现该接口;代表着消费者。
- Producer:生产者接口,第三方线程充当该角色,producer向RingBuffer写入事件。
- Wait Strategy:等待策略,Wait Strategy决定了一个消费者怎么等待生产者将事件(Event)放入Disruptor中。常用的三个:
- BlockingWaitStrategy(常用):使用ReentrantLock,失败则进入等待队列等待唤醒重试。当吞吐量和低延迟不如CPU资源重要时使用。
- YieldingWaitStrategy(常用):尝试100次,全失败后调用Thread.yield()让出CPU。该策略将使用100%的CPU,如果其他线程请求CPU资源,这种策略更容易让出CPU资源。
- SleepingWaitStrategy(常用):尝试200次 。前100次直接重试,后100次每次失败后调用Thread.yield()让出CPU,全失败线程睡眠(默认100纳秒 )。
说明:
- 生产者(producer)向RingBuffer中加入事件,生产方只维护一个代表生产的最后一个元素的序号。代表生产的最后一个元素的序号。每次向Disruptor发布一个元素都调用Sequenced.next()来获取下个位置的写入权。。
- 消费者(EventHandler)从RingBuffer中读取事件,但是读取之前会通过 SequenceBarrier 检查事件是否准备好,如果事件已准备好,消费者调用 get() 方法从 RingBuffer 中读取事件,并通过自己的 Sequence 更新处理进度
- SequenceBarrier,引用 Sequencer 的实例来跟踪生产者的序列号,检查事件是否已经发布(根据序列号),判断消费者是否可以安全地读取事件,假如消费者的序列号对应的事件还没有生产者生产出来,那么SequenceBarrier就会执行等待策略WaitStrategy。
- 消费者之间可以有依赖关系。例如:JournalConsumer 完成后, ReplicationConsumer 才能处理事件,ApplicationConsumer 可能依赖于前两个消费者的结果。这种依赖关系通过 SequenceBarrier 和 Sequence 协调。
使用
Event 是具体的数据实体,生产者生产 Event ,存入 RingBuffer,消费者从 RingBuffer 中消费它进行逻辑处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| public class TaskEvent<T> {
private long taskId;
private T payload;
private final AtomicBoolean processed = new AtomicBoolean(false);
public TaskEvent() {
}
public TaskEvent(long taskId, T payload) {
this.taskId = taskId;
this.payload = payload;
}
public boolean setProcessed() {
return processed.compareAndSet(false, true);
}
public boolean getProcessed() {
return processed.get();
}
public long getTaskId() {
return taskId;
}
public void setTaskId(long taskId) {
this.taskId = taskId;
}
public T getPayload() {
return payload;
}
public void setPayload(T payload) {
this.payload = payload;
}
}
|
定义EventFactory用于创建Event对象:
1
2
3
4
5
6
7
| public class TaskEventFactory<T> implements EventFactory<TaskEvent<T>> {
@Override
public TaskEvent<T> newInstance() {
return new TaskEvent<>();
}
}
|
定义生产者:生成者主要是持有 RingBuffer 对象进行数据的发布。在 RingBuffer 初始化时该 Object 数组就已经使用 EventFactory 初始化了一些空 Event,后续就不需要在运行时来创建了,提高性能。因此这里通过 RingBuffer 获取指定序号得到的是一个空对象,需要对它进行赋值后,才能进行发布。通过 RingBuffer 的 next 方法获取可用序号,如果 RingBuffer 空间不足会阻塞。通过 next 方法获取序号后,需要确保接下来使用 publish 方法发布数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| public class TaskProducer<T> {
private final RingBuffer<TaskEvent<T>> ringBuffer;
public TaskProducer(DisruptorQueue<T> queue) {
Disruptor<TaskEvent<T>> disruptor = queue.getDisruptor();
this.ringBuffer = disruptor.getRingBuffer();
}
public void push(TaskEvent<T> event) {
long sequence = ringBuffer.next();
try {
TaskEvent<T> taskEvent = ringBuffer.get(sequence);
taskEvent.setTaskId(event.getTaskId());
taskEvent.setPayload(event.getPayload());
} finally {
ringBuffer.publish(sequence);
}
}
}
|
定义消费者:消费者可以实现 EventHandler 接口,定义自己的处理逻辑。这里是一个抽象类,简化代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public abstract class AbstractTaskConsumer<T> implements EventHandler<TaskEvent<T>> {
private final Logger logger = LoggerFactory.getLogger(AbstractTaskConsumer.class);
@Override
public void onEvent(TaskEvent<T> event, long sequence, boolean endOfBatch) throws Exception {
if (event.markAsProcessed()) {
logger.info("consumer sequence: {}", sequence);
try {
bizHandler(event);
} catch (Exception e) {
throw e;
}
}
}
protected abstract void bizHandler(TaskEvent<T> event);
}
|
封装Disruptor,简化初始化过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| public class DisruptorQueue<T> {
public static final Integer DEFAULT_BUFFER_SIZE = 4096 << 1 << 1;
private final Disruptor<TaskEvent<T>> disruptor;
public DisruptorQueue() {
this(DEFAULT_BUFFER_SIZE);
}
public DisruptorQueue(int bufferSize) {
this(bufferSize, ProducerType.SINGLE, new BlockingWaitStrategy(),
new DefaultThreadFactory("default-disruptor"));
}
public DisruptorQueue(int bufferSize, ThreadFactory threadFactory) {
this(bufferSize, ProducerType.SINGLE, new BlockingWaitStrategy(), threadFactory);
}
public DisruptorQueue(int bufferSize, ProducerType producerType, WaitStrategy waitStrategy,
ThreadFactory threadFactory) {
this.disruptor = new Disruptor<>(
new TaskEventFactory<>(),
bufferSize,
threadFactory,
producerType,
waitStrategy);
}
@SafeVarargs
public final void start(AbstractTaskConsumer<T>... consumer) {
disruptor.handleEventsWith(consumer);
disruptor.start();
}
public Disruptor<TaskEvent<T>> getDisruptor() {
return this.disruptor;
}
public void shutdown() throws TimeoutException {
disruptor.shutdown(5, TimeUnit.SECONDS);
}
}
|
上面的代码实现的一个通用的业务处理逻辑,下面的具体的业务使用:
具体的业务BizTaskConsumer:
1
2
3
4
5
6
7
8
9
| public class BizTaskConsumer extends AbstractTaskConsumer<User> {
private static final Logger logger = LoggerFactory.getLogger(BizTaskConsumer.class);
@Override
protected void bizHandler(TaskEvent<User> event) {
logger.info("biz consumer, taskId: {}, payload: {}", event.getTaskId(), event.getPayload());
}
}
|
使用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public static void main(String[] args) throws Exception {
DisruptorQueue<User> queue = new DisruptorQueue<>();
BizTaskConsumer[] consumers = new BizTaskConsumer[4];
for (int i = 0; i < 4; i++) {
consumers[i] = new BizTaskConsumer();
}
queue.start(consumers);
TaskProducer<User> producer = new TaskProducer<>(queue);
for (long i = 0; i < 10L; i++) {
MDC.put("traceId", String.valueOf(i));
logger.info("id: {}", i);
TaskEvent<User> taskEvent = new TaskEvent<>();
taskEvent.setTaskId(Instant.now().toEpochMilli());
taskEvent.setPayload(new User(i, "ares"));
producer.push(taskEvent);
}
queue.shutdown();
}
|
核心源码分析
成员变量:
1
2
3
4
5
6
| public class Disruptor<T>
{
private final RingBuffer<T> ringBuffer;
private final ThreadFactory threadFactory;
......
}
|
这里着重看下 RingBuffer:
1
2
3
4
5
6
7
| abstract class RingBufferFields<E> extends RingBufferPad
{
private final long indexMask;
private final E[] entries;
protected final int bufferSize;
protected final Sequencer sequencer;
}
|
E[] entries:为RingBuffer的存储数组。
Disruptor创建
1
2
3
4
5
6
7
8
| public Disruptor(
final EventFactory<T> eventFactory,
final int ringBufferSize,
final Executor executor,
final ProducerType producerType,
final WaitStrategy waitStrategy){
this(RingBuffer.create(producerType, eventFactory, ringBufferSize, waitStrategy), executor);
}
|
RingBuffer.create():
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public static <E> RingBuffer<E> create(
final ProducerType producerType,
final EventFactory<E> factory,
final int bufferSize,
final WaitStrategy waitStrategy){
switch (producerType)
{
case SINGLE:
return createSingleProducer(factory, bufferSize, waitStrategy);
case MULTI:
return createMultiProducer(factory, bufferSize, waitStrategy);
default:
throw new IllegalStateException(producerType.toString());
}
}
|
在 RingBuffer 创建时,分为单生产者与多生产者。不论是单生产者还是多生产者,最终都会创建一个 RingBuffer 对象,只是传给 RingBuffer 的 Sequencer 对象不同,RingBuffer 内部最终创建了一个Object 数组来存储 Event 数据。RingBuffer创建我们需要注意:
- RingBuffer 在创建该数组后紧接着调用 fill 方法调用 EventFactory 工厂方法为数组中的元素进行初始化,后续在使用这些元素时,直接通过下标获取并给对应的属性赋值,这样就避免了 Event 对象的反复创建,避免频繁 GC。
- RingBuffe 的数组中的元素是在初始化时一次性全部创建的,所以这些元素的内存地址大概率是连续的。消费者在消费时,是遵循空间局部性原理的。消费完第一个Event 时,很快就会消费第二个 Event,而在消费第一个 Event 时,CPU 会把内存中的第一个 Event 的后面的 Event 也加载进 Cache 中,这样当消费第二个 Event时,它已经在 CPU Cache 中了,所以就不需要从内存中加载了,这样可以大大提升性能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| RingBufferFields(
EventFactory<E> eventFactory,
Sequencer sequencer){
this.entries = new Object[sequencer.getBufferSize() + 2 * BUFFER_PAD];
fill(eventFactory);
}
private void fill(EventFactory<E> eventFactory){
for (int i = 0; i < bufferSize; i++){
entries[BUFFER_PAD + i] = eventFactory.newInstance();
}
}
|
消费者与消费
在 Disruptor 启动之前需要添加 Consumer 并启动消费者线程:
1
2
| disruptor.handleEventsWith(consumer);
disruptor.start();
|
具体源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| @SafeVarargs
public final EventHandlerGroup<T> handleEventsWith(final EventHandler<? super T>... handlers)
{
return createEventProcessors(new Sequence[0], handlers);
}
EventHandlerGroup<T> createEventProcessors(
final Sequence[] barrierSequences,
final EventHandler<? super T>[] eventHandlers)
{
checkNotStarted();
final Sequence[] processorSequences = new Sequence[eventHandlers.length];
final SequenceBarrier barrier = ringBuffer.newBarrier(barrierSequences);
for (int i = 0, eventHandlersLength = eventHandlers.length; i < eventHandlersLength; i++)
{
final EventHandler<? super T> eventHandler = eventHandlers[i];
final BatchEventProcessor<T> batchEventProcessor =
new BatchEventProcessorBuilder().build(ringBuffer, barrier, eventHandler);
if (exceptionHandler != null)
{
batchEventProcessor.setExceptionHandler(exceptionHandler);
}
consumerRepository.add(batchEventProcessor, eventHandler, barrier);
processorSequences[i] = batchEventProcessor.getSequence();
}
updateGatingSequencesForNextInChain(barrierSequences, processorSequences);
return new EventHandlerGroup<>(this, consumerRepository, processorSequences);
}
|
disruptor.start():Disruptor的启动就是遍历consumerRepository 中收集的 EventProcessor(实现了Runnable接口),将它提交到创建 Disruptor 时指定的executor 中,EventProcessor 的 run 方法会启动一个while 循环,不断尝试从 RingBuffer 中获取数据进行消费。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public RingBuffer<T> start()
{
checkOnlyStartedOnce();
consumerRepository.startAll(threadFactory);
return ringBuffer;
}
public void startAll(final ThreadFactory threadFactory)
{
consumerInfos.forEach(c -> c.start(threadFactory));
}
public void start(final Executor executor) {
executor.execute(eventprocessor);
}
|
消费:Disruptor 启动时,会将封装 EventHandler 的EventProcessor(此处以 BatchEventProcessor 为例)提交到线程池中运行,BatchEventProcessor 的 run 方法会调用 processEvents 方法不断尝试从 RingBuffer 中获取数据进行消费。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| @Override
public void run() {
int witnessValue = running.compareAndExchange(IDLE, RUNNING);
if (witnessValue == IDLE) {
省略
if (running.get() == RUNNING) {
processEvents();
}
省略
}
}
private void processEvents() {
T event = null;
long nextSequence = sequence.get() + 1L;
while (true) {
final long startOfBatchSequence = nextSequence;
try {
final long availableSequence = sequenceBarrier.waitFor(nextSequence);
final long endOfBatchSequence = min(nextSequence + batchLimitOffset, availableSequence);
if (nextSequence <= endOfBatchSequence) {
eventHandler.onBatchStart(endOfBatchSequence - nextSequence + 1, availableSequence - nextSequence + 1);
}
while (nextSequence <= endOfBatchSequence) {
event = dataProvider.get(nextSequence);
eventHandler.onEvent(event, nextSequence, nextSequence == endOfBatchSequence);
nextSequence++;
}
retriesAttempted = 0;
sequence.set(endOfBatchSequence);
}
}
|
在 waitStrategy 的 waitFor 方法返回,得到最大可用的序号 availableSequence 后,最后需要再调用下 sequencer 的 getHighestPublishedSequence 获取真正可用的最大序号,这和生产者模型有关系,如果是单生产者,因为数据是连续发布的,直接返回传入的 availableSequence。而如果是多生产者,因为多生产者是有多个线程在生产数据,发布的数据是不连续的,因此需要通过 getHighestPublishedSequence 方法获取已发布的且连续的最大序号,因为获取序号进行消费时需要是顺序的,不能跳跃。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| @Override
public long waitFor(final long sequence) throws AlertException, InterruptedException, TimeoutException {
checkAlert();
long availableSequence = waitStrategy.waitFor(sequence, cursorSequence, dependentSequence, this);
if (availableSequence < sequence) {
return availableSequence;
}
return sequencer.getHighestPublishedSequence(sequence, availableSequence);
}
@Override
public long waitFor(final long sequence, final Sequence cursorSequence, final Sequence dependentSequence, final SequenceBarrier barrier) throws AlertException, InterruptedException {
long availableSequence;
if (cursorSequence.get() < sequence){
synchronized (mutex) {
while (cursorSequence.get() < sequence) {
barrier.checkAlert();
mutex.wait();
}
}
}
while ((availableSequence = dependentSequence.get()) < sequence){
barrier.checkAlert();
Thread.onSpinWait();
}
return availableSequence;
}
|
dependentSequence:消费者依赖的前置消费者的消费进度。该字段是在添加 EventHandler,创建BatchEventProcessor 时创建的。如果当前消费者没有前置依赖的消费者,那么它只需要关心生产者的进度,生产者生产到哪里,它就可以消费到哪里,因此 dependentSequence 就是 cursor。而如果当前消费者有前置依赖的消费者,那么dependentSequence就是FixedSequenceGroup(dependentSequences)。dependentSequence 分为两种情况,所以 waitFor 的逻辑也可以分为两种情况讨论:
- 当前消费者无前置消费者时,当生产者继续发布数据后,因为 dependentSequence 持有的就是生产者的生成进度,因此消费者可以感知到,继续消费。
- 当前消费者有前置消费者时,需要等待最慢的消费者序列号追上才能往后消费。
生产者与发布
我们先看下业务发布入口:
1
2
3
4
5
6
7
8
9
10
| public void push(TaskEvent<T> event) {
long sequence = ringBuffer.next();
try {
TaskEvent<T> taskEvent = ringBuffer.get(sequence);
taskEvent.setTaskId(event.getTaskId());
taskEvent.setPayload(event.getPayload());
} finally {
ringBuffer.publish(sequence);
}
}
|
业务发布逻辑:
- 调用 next 方法获取可用序号,该方法可能会阻塞。
- 通过上一步获得的序号从 RingBuffer 中获取对应的 Event,因为 RingBuffer 中所有的 Event 在初始化时已经创建好了,这里获取的只是空对象。
- taskEvent 进行业务赋值。
- 在 finally 方法中进行最终的发布
ringBuffer.publish(sequence),标记该序号数据已实际生产完成。
next方法:next 方法默认申请一个序号。nextValue 表示已分配的序号,nextSequence 表示在此基础上再申请n个序号(此处n为1),cachedValue 表示缓存的消费者的最小消费进度。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| @Override
public long next(final int n){
long nextValue = this.nextValue;
long nextSequence = nextValue + n;
long wrapPoint = nextSequence - bufferSize;
long cachedGatingSequence = this.cachedValue;
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > nextValue) {
cursor.setVolatile(nextValue);
long minSequence;
while (wrapPoint > (minSequence = Util.getMinimumSequence(gatingSequences, nextValue))) {
LockSupport.parkNanos(1L);
}
this.cachedValue = minSequence;
}
this.nextValue = nextSequence;
return nextSequence;
}
|
发布数据:生产者获取到可用序号后,对Event 对象进行业务赋值后,最后调用 RingBuffer 的 publish 方法发布数据,RingBuffer 会委托给其持有的 sequencer(单生产者和多生产者对应不同的 sequencer)对象进行真正发布。单生产者的发布逻辑比较简单,更新下 cursor 进度(cursor 表示生产者的生产进度,该位置已实际发布数据,而 next 方法中的 nextSequence 表示生产者申请的最大序号,可能还未实际发布数据),接着唤醒等待的消费者。
1
2
3
4
5
6
7
8
9
10
11
| @Override
public void publish(final long sequence){
sequencer.publish(sequence);
}
public void publish(long sequence) {
cursor.set(sequence);
waitStrategy.signalAllWhenBlocking();
}
|
总结
Disruptor 是基于生产者消费者模式,如果生产快消费慢,就会导致生产者无法写入数据,不建议在 Disruptor 消费线程中处理耗时较长的业务。另外,每一个 EventHandler 对应一个线程,一个线程只服务于一个 EventHandler,在创建 Disruptor 时不推荐传入指定的线程池,而是由 Disruptor 自身根据 EventHandler 数量去创建对应的线程。消费者在获取不到数据时会根据设置的等待策略进行等待,BlockingWaitStrategry 是最低效的策略,但其对 CPU消耗最小,YieldingWaitStrategy 有着较低的延迟、较高的吞吐量,以及较高 CPU 占用率。生产者调用 next 方法申请序号时,如果获取不到可用序号会阻塞,可以使用 tryPublishEvent 方法,生产者在申请不到可用序号时会立即返回,不会阻塞业务线程。