ForkJoinPool 基础
概述
ForkJoinPool 是 Java 7 引入的用于并行执行“分而治之”任务的线程池,它是 ExecutorService 接口的一个特殊实现,其核心设计目标是高效地处理那些可以递归分解成更小任务的工作负载。其工作方式采取工作窃取算法,以避免工作线程由于拆分了任务之后的join等待过程,这样处于空闲的工作线程将从其他工作线程的队列中主动去窃取任务来执行。
分而治之
分治法的基本思想是将一个规模为N的问题分解为K个规模较小的子问题,这些子问题的相互独立且与原问题的性质相同,求出子问题的解之后,将这些解合并,就可以得到原有问题的解,是一种分目标完成的程序算法。
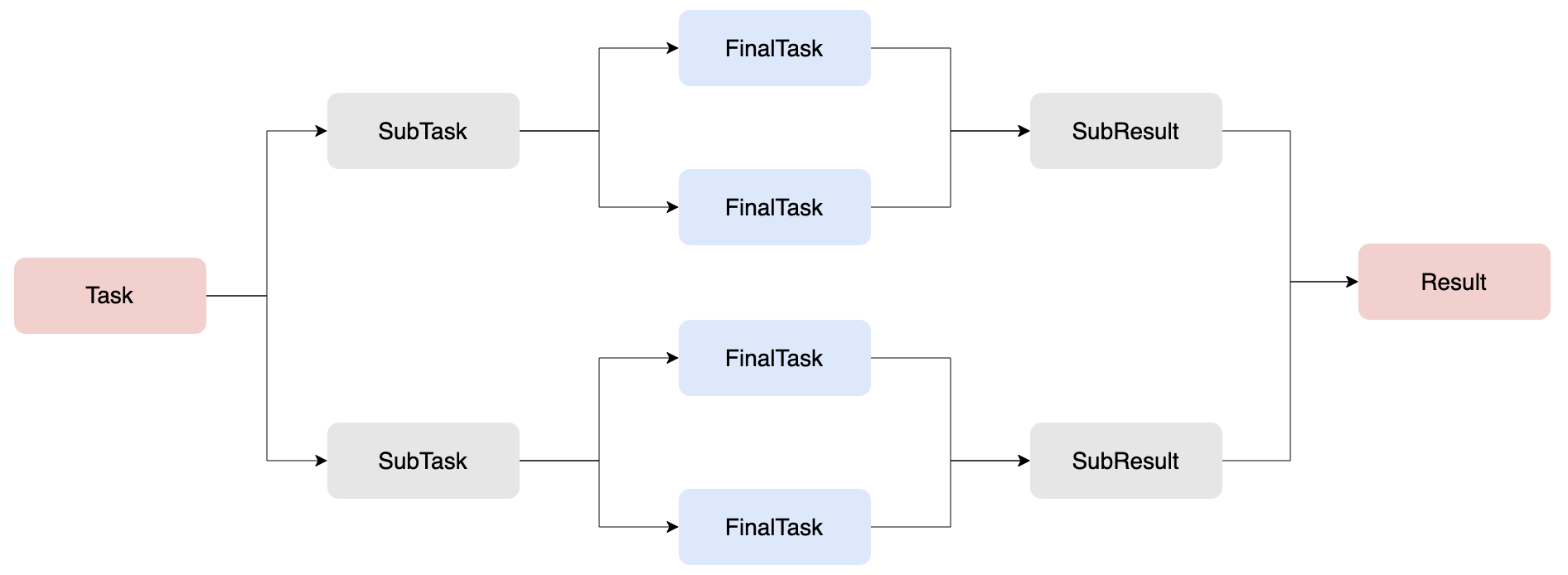
实现分治思想通常涉及三个步骤:
- 分解 (Divide/Fork):将一个复杂的大任务拆解成多个相互独立的、更小的子任务。这个过程是递归进行的。
- 解决 (Conquer/Compute):当任务被分解到足够小,无法再拆分时(达到了预设的阈值),就直接执行这个小任务。
- 合并结果 (Combine/Join):等待所有子任务完成后,将它们的结果汇总起来,形成最终大任务的结果。
工作窃取算法
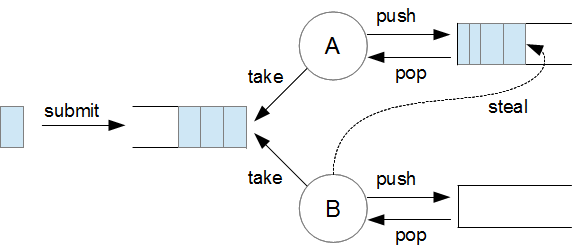
工作窃取算法的基本思想是将任务队列分配给每个线程,并通过线程间的协作来完成任务的执行。每个线程都有自己的任务队列,当一个线程执行完自己队列中的任务后,它会去其他线程的队列中窃取任务来执行。其逻辑如下:
- 本地队列:每个线程都有一个自己的本地任务队列,用于存放待执行的任务,这些任务通常是由当前线程创建或分配的。
- 窃取任务:当一个线程执行完自己队列中的任务后,它会去其他线程的队列中偷取任务来执行。通常情况下,线程会选择窃取其他线程队列中的末尾位置(或近似末尾位置)的任务,因为这些任务最可能是最近添加的,即最新的任务。
- 动态调整:工作窃取算法具有一定的自适应性,它会根据当前系统的负载情况动态地调整任务的分配策略。例如,当一个线程的本地队列为空时,它会去窃取其他线程的任务来执行。当一个线程的本地队列过长时,它可能会主动将部分任务分配给其他线程。
工作窃取算法的优点是能够减少线程之间的竞争和同步开销,提高并行性能,它利用了多核处理器的特性,使得任务可以在多个处理单元上并行执行,从而提高了系统的整体吞吐量和响应速度。
ForkJoinPool基础
在JUC中,ForkJoinPool 的实现依赖于三个关键类:
- ForkJoinPool: 线程池的核心管理类,负责协调和管理工作线程,实现工作窃取算法,并提供任务提交的入口。
- ForkJoinWorkerThread: 实际执行任务的工作线程。每个工作线程都绑定一个私有的任务队列。
- ForkJoinTask: 抽象的任务类,定义了 fork()(提交子任务)和 join()(等待子任务完成并合并结果)等操作。开发者通常继承其子类 RecursiveAction 或 RecursiveTask 来实现具体的业务逻辑。
一般我们要定义Fork/Join任务是直接继承ForkJoinTask的子类,Fork/Join框架提供了两个子类:
- RecursiveAction:递归无结果的ForkJoinTask——没有返回值任务(类似于 Runnable)。
- RecursiveTask:递归有结果的ForkJoinTask——有返回值任务(类似于 Callable)。
ForkJoinPool的核心功能:
- 管理工作线程:ForkJoinPool会管理一组ForkJoinWorkerThread,这些工作线程用于执行提交给线程池的任务。
- 自适应并行度:默认情况下,线程池的并行度(parallelism)与可用的处理器数量相等,从而最大限度地利用硬件资源。
- 高效调度:它不依赖操作系统调度,而是通过其内部的工作窃取算法来高效地调度任务。
ForkJoinPool 提交任务方法:
基于 ForKJoinTask 实现 Fibonacci计算,使用Fork/Join框架实现一个计算Fibonacci任务
1 | |
对于上的 compute() 方法有如下几种实现:
- fork() + compute() + join():
1 | |
上面代码执行时,当前线程将 left 任务提交到队列,然后它自己并不等待,而是立即开始通过 right.compute() 同步地计算 right 任务。该线程没有被浪费,它在积极地完成一半的工作(计算 right)。与此同时,left 任务在队列中,可以被线程池中的另一个空闲线程“窃取”(work-stealing) 并行执行。这是 Fork/Join 框架推荐的标准模式。它实现了一个任务(left)异步化,另一个任务(right)本地化,从而最大化地利用了 CPU 资源,避免了不必要的线程阻塞。
注意:为了实现更好的负载均衡,并减少窃取开销,总是 fork() 那个计算量更大的任务,compute() 那个计算量更小的任务。在上面代码中left = new FibonacciTask(n - 1) 任务更大,right = new FibonacciTask(n - 2) 任务更小。为什么呢?这是因为 工作窃取(Work-Stealing)机制 :
- fork() 的作用: 当一个工作线程(Worker Thread)调用 task.fork(),它会将这个 task 放入自己的工作队列(一个双端队列,Deque)中。这个任务现在就可以被其他空闲线程窃取。
- compute() 的作用: 线程自己立即开始执行这个任务。
- 窃取的发生: 当一个线程 A 变得空闲时(它完成了自己的所有工作),它会随机查看另一个线程 B 的工作队列,并从队列的另一端窃取一个任务来执行。
因此:在 Fork/Join 模式中,更优的做法是:
- 把最大的那份工作 fork() 出去(推到队列里),让最有空的“同事”(其他线程)去认领。
- 你自己立即开始 compute() 最小的那份工作,以保持自己忙碌。
这样可以确保偷窃者(Idle Threads)总能拿到“值得偷”的大块任务,从而最大限度地减少了它们在“寻找工作”上花费的开销,实现了最高效的负载均衡。
- invokeAll()+join()+join():
1 | |
ForkJoinTask.invokeAll() 是一个静态辅助方法,专门用于简化执行一组子任务并等待它们全部完成的场景。一行代码完成了分支、执行、等待三件事,invokeAll() 本质上就是 fork/compute/join 模式的官方封装。在绝大多数情况下,优先使用 invokeAll()。它更安全、更简洁,可读性更高,并且性能与fork/compute/join 模式所能达到的效果一样好。只有在极少数需要“非对称”处理的复杂场景下(例如,fork(left) 之后,不需要 compute(right),而是想在 join(left) 之前执行一些完全不同的逻辑),才需要回退到手动的 fork/compute/join 模式。
- fork() + fork() + join() + join()
1 | |
上面代码执行时,当前线程(一个 Worker 线程)将 left 任务和 right 任务都提交到工作队列中,期望其他线程去执行它们。但是这里导致一个问题:提交任务后,当前线程立即调用 left.join() 进入阻塞(waiting)状态,它什么也不做,只是干等着 left 任务完成。本来这个 Worker 线程本可以用来执行 right 任务,但它却被浪费在等待上了,如果所有线程都像这样 fork 完就 join,线程池中的线程会很快全部进入等待状态,导致没有活动线程来实际执行队列中的任务——“线程饥饿” (Thread Starvation)。
自定义 ForkJoinWorkerThreadFactory
ForkJoinPool.ForkJoinWorkerThreadFactory 的作用是为 ForkJoinPool 创建其内部的工作线程 (ForkJoinWorkerThread)。它是一个接口,定义了创建新线程的方法,使得开发者能够控制 ForkJoinPool 中工作线程的特性:
- 自定义工作线程属性: 允许开发者设置工作线程的名称、优先级、守护状态 (daemon status) 和异常处理器等。
- 集成安全管理器 (SecurityManager): 在有安全管理器运行的环境中,工厂负责创建具有正确安全上下文和权限的工作线程。ForkJoinPool 的默认工厂 defaultForkJoinWorkerThreadFactory 就是一个能处理此情况的例子。
- 扩展 ForkJoinWorkerThread: 允许开发者使用自定义的 ForkJoinWorkerThread 子类。这对于需要在工作线程启动时执行额外初始化逻辑或存储线程本地状态的场景非常有用。
- 解耦线程创建逻辑: 将线程池的核心调度逻辑与具体的线程创建细节分离,提高了代码的模块化和灵活性。
下面示例是通过自定义 CustomWorkerThreadFactory 实现在ForkJoinPool中MDC上下文传递。其主要在 onStart() 将父线程的 traceId 传递给子线程,在 onTermination() 中进行清理。
1 | |
使用
1 | |
ForkJoinTask执行流程
提交 (Submission):外部客户端(例如 main 线程)创建一个 ForkJoinPool,然后调用其 invoke(RootTask) 或 execute(RootTask) 方法来提交一个“根任务”。ForkJoinPool 接收到这个任务,并将其放入一个全局等待队列中,或者直接分配给一个空闲的工作线程。
执行与分支 (Execution & Fork):一个工作线程(比如 线程 A)获得了这个 RootTask 并开始执行它的 compute() 方法。在 compute() 内部(标准模式):
- 检查基准条件:任务首先检查自己是否已经“足够小”,小到不需要再拆分(例如,n <= 1)。如果是,则直接计算并返回结果。
- 拆分 (Divide):如果任务太大,它会拆分为两个(或更多)子任务,例如 LeftTask 和 RightTask。
- left.fork():线程 A 调用 LeftTask.fork()。线程 A 会将 LeftTask 推入 (push) 到它自己的本地工作队列的底部 (bottom/head)。这相当于说:“我稍后会处理这个,或者谁闲了就来拿吧。”
- right.compute():线程 A 不会 fork 右边的任务,而是立即开始同步递归地执行 RightTask.compute()。
工作窃取 (Work-Stealing):此时,线程 B(池中的另一个工作线程)完成了它所有的工作,它的本地队列空了。线程 B 变为空闲状态,它不能闲着。它会随机挑选另一个工作线程(比如 线程 A)。线程 B 会查看 线程 A 的队列,并从队列的顶部 (top/tail) “窃取” (steal) 一个任务。使用一端推另一端偷可以最大限度地减少线程间的竞争,两个线程操作队列的不同端。线程 B 拿到了 LeftTask 并开始执行它的 compute() 方法。现在,LeftTask 和 RightTask(的一部分)就在并行执行了。
合并 (Join):如果线程 A 完成了 right.compute() 以及它的所有子任务。left.join() 线程 A 获取LeftTask 的结果。join()过程会检查状态,线程 A 首先检查 LeftTask 是否已经完成:
- 已被窃取且已完成:如果 LeftTask 已被线程 B 偷走并执行完毕,join() 会立即获取结果并返回。
- 仍在队列中(未被窃取):如果 LeftTask 仍然在线程 A 自己的队列中(没有线程来偷),线程 A 会将其从队列中取出并自己执行它。
- 已被窃取但未完成:如果 LeftTask 正被线程 B 执行,线程 A 通常也不会立即阻塞。它会先尝试执行自己队列中的其他任务,或者去“帮助”执行其他被偷的任务。在万不得已时(实在没事干了),它才会真正地阻塞 (block) 等待。
返回 (Conquer):线程 A 获得了 LeftTask 和 RightTask 的结果,将它们合并。RootTask 的 compute() 方法执行完毕,返回最终结果。main 线程的 invoke() 调用结束,获得最终结果。
FonkJoinPool 适用场景
ForkJoinPool 是 Java 7 引入的一个专为并行执行可分解任务而设计的线程池,它主要用于实现“分而治之”的算法。其核心原理是工作窃取 (work-stealing) 算法,旨在充分利用多核 CPU 资源,提高并行计算效率。 ForkJoinPool 最适合处理计算密集型且符合分治思想的任务,它不是为了替代 ThreadPoolExecutor,而是其补充。 其适用场景:
- 大规模数据处理
- 数组求和或查找:计算大型数组中所有元素的总和,或查找特定元素。
- 图像处理:对图像的不同区域进行并行处理,例如应用滤镜、调整色彩或进行变换。
- 大数据分析:将海量数据集分解成小块,并行进行分析、聚合或转换操作。
- 递归算法优化
- 并行排序:将传统的“分而治之”排序算法(如快速排序和归并排序)并行化,提升处理大规模数据集的效率。
- 树状结构遍历:并行遍历树形结构,可以用于文件系统搜索、XML解析等。
- 科学计算和模拟
- 矩阵运算:将大型矩阵的乘法、加法等运算分解为子任务,并行执行。
- 数值模拟:在各种需要大量计算的科学和工程模拟中,将计算任务并行化。
- Java Stream API 的底层支持——并行流(Parallel Streams):Java 8及以上版本的并行流API在底层就是使用ForkJoinPool来执行并行操作。例如,对一个集合进行parallelStream()操作,就会自动使用ForkJoin框架。
然而对于I/O 密集型任务、任务粒度过小、任务之间强依赖性的任务并不适用:
- I/O 密集型任务:如果任务涉及大量的阻塞 I/O 操作(如网络请求、文件读写),线程可能会长时间阻塞,这会严重影响 ForkJoinPool 的性能和并行度。
- 任务粒度过小:如果子任务太小,fork() 和 join() 操作以及任务管理的开销可能会超过并行执行带来的收益。
- 任务之间强依赖性:如果子任务之间需要频繁通信或相互等待,工作窃取机制的效率会降低。